
[CV Study] Spatial Transformer Networks (NIPS '15)
2020. 5. 30. 23:58ㆍResearch
Motivation: 딥러닝 학습시에 왜곡된 이미지를 데이터셋으로 활용하려면 어떻게 해야할까? 이미지의 왜곡을 자동으로 disentangle 해줄 수는 없을까?
Introduction
기존 CNN의 한계
- CNN은 spatially invariant하지 못하다. 즉 scale, rotation, translation과 같은 위치/공간 상의 변화에 대해서 제대로 대응하지 못한다.
- Local max pooling을 통해서 이러한 점을 어느 정도 완화할 수도 있지만 pooling size가 작을 수록 그 효과는 미미해진다.
이를 해결하기 위한 것이 Spatial Transformer!
- Pooling layer와의 차이점은?
- Pooling layer는 pooling size가 fix 되어 있고 그 범위가 매우 한정되어 있지만, spatial transformer는 동적으로 각각의 이미지에 맞는 transformation을 만들어 준다.
- Pool size 단위로 적용되는 pooling과는 다르게 spatial transformer는 Feature map 전체에 대해서 transformation을 적용!
- Input image 상에서 가장 중요한 부분에 attention을 주어 그 부분만 추출할 수 있다.
- Transformation을 계산하기 위한 별도의 과정 없이 기존 CNN 모델들의 구조 속에 ST layer를 삽입하고, 이전과 같이 학습을 시키면 된다. 즉, ST layer는 전체 네트워크에 포함되어 backprop을 통해 함께 E2E 학습 가능하다.
- 여러 종류의 task들에 활용 가능:
- image classification
- co-localisation
- spatial attention
예시)

Spatial Transformers

사실상 위의 그림(Figure 2)이 이 논문의 전부라고 볼 수 있다. 위 그림은 ST layer 하나가 어떻게 동작하는지 보여준다. 이 그림의 각 단계에 대해 하나하나 살펴보자.
Workflow
ST layer 내에서 데이터의 흐름은 다음과 같다.
- Input feature map $U$가 localisation net에 들어가서 transformation parameter $\theta$를 뽑아낸다.
- 이 때 localisation net의 구조는 convolution net이든 FC net이든 상관 없고, 마지막에 regression layer만 잘 들어가서 parameter 추출만 잘 하면 된다.
- 앞에서 뽑아낸 transformation parameter $\theta$는 grid generator에 들어가서 샘플링 지점의 위치가 지정된 sampling grid $T_{\theta}(G)$를 생성한다.
- Sampler에는 Input feature map $U$와 sampling grid $T_{\theta}(G)$가 입력으로 들어간다.
- sampling grid $T_{\theta}(G)$에는 sampling point가 찍혀있기 때문에 그것을 input feature map $U$에 적용하면 output feature map $V$를 뽑아낼 수 있음.
이 흐름에 대해서만 이해를 하면 이 논문을 이해한 것인데, 각 과정에 대해서 좀 더 자세히 살펴보자.
1. Localisation Network
- $U$에 적용할 transformation parameter $\theta$를 추정한다.
- 이 때 $\theta$는 parameter matix인데 그 shape은 transformation의 종류에 따라서 달라진다.
- 예를 들어 아핀 변환의 경우엔 6차원
- Convolution layer로 구성되든 FC layer로 구성되든 상관 없고 마지막에 regression layer만 잘 들어가면 된다. (최종적으로 parameter 값을 뽑아야 하므로)
2. Parameterized Sampling Grid

- Grid generator는 $\theta$에 따라서 input feature map $U$ 상에서 sampling할 포인트를 정해주는 sampling grid $T_{\theta}(G)$를 계산한다.
- Output feature map $V$는 input feature map $U$와 마찬가지로 일반적인 직사각형 그리드 내에 위치한다. 이와 같은 출력 feature map grid를 $G$라고 함.
- Input feature map $U$의 grid 상에 찍힌 sampling point 집합인 $T_{\theta}(G)$와 $G$는 transformation $T_{\theta}$를 통해서 서로 매핑된다.
(1) 아핀 변환의 예시

(2) 보다 contraint가 많은 attention 변환의 예시

- 위의 두 가지 예시 이외에 어떠한 parameterised form의 변환도 가능하다.
- 즉, $T_{\theta}$의 각 configuration parameter들에 대해서 미분가능하기만 하면 된다.
- 미분가능하기만 하면 parameter들이 backprop 과정에서 optimize 가능하다.
- 참고) 당연한 이야기이지만, $T_{\theta}$가 contrained 되어 있을 수록 연산 complexity는 낮아진다.
3. Differentiable Image Sampling
$Sample(T_{\theta}(G), \ U) \to V$
- Input feature map $U$ 상의 sampling grid인 $T_{\theta}(G)$를 input feature map $U$에 적용하여 output feature map $V$를 생성한다.
- $T_{\theta}(G)$가 가진 정보는? $U$에서 어느 포인트의 값을 뽑아낼지에 대한 정보
- 다음의 식을 통해서 $V$의 $i$번째 픽셀 값을 얻어낼 수 있다.

- 이미지 픽셀은 discrete한 정수형 좌표값을 가지기 때문에 floating point 값으로 계산된 위치 좌표값을 가장 가까운 정수 좌표값으로 rounding할 필요가 있다.
- $(x_i^s, y_i^s)$의 좌표(FP32)에 가장 가까운 정수 좌표(INT32) 픽셀의 데이터 값을 그에 대응되는 $V$의 위치 $(x_i^t, y_i^t)$에 복사.
(1) Nearest Integer Sampling
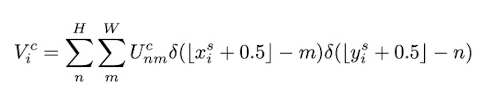
(2) Bilinear Sampling
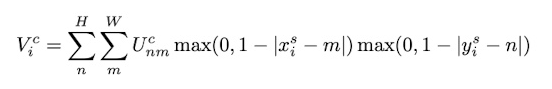
- $U$와 $G$에 대해서 미분 가능하면 backprop 가능하다.
- 미분 불가능한 구간이 있더라도 구간별로 나눠서 backprop하면 되기 때문에 문제 없다.

Spatial Transformer Network
- 위의 구조들을 모두 합쳐서 만들어진 ST layer를 CNN 모델들 중간 중간에 끼워넣은 것이 ST Network.
- Transformation은 traininig 과정 중에 모델 내의 다른 파라미터들과 함께 학습이 되기 때문에 training 속도 자체에 미치는 영향이 거의 없다.
- CNN 입력 바로 앞에 ST layer를 두는 것이 evaluation 결과를 보았을 때 일반적으로 가장 효과적이다.
Evaluation
1. Distorted MNIST

-
Tranformation 종류
- R: Rotaion
- RTS: Rotation, Translation, Scale
- P: Projective transformation
- E: Elastic warping
-
CNN 앞에 ST를 추가한 ST-CNN의 성능이 가장 좋다.
-
왜 FCN보다 CNN이 나은가?
- Max pooling이 spatial invariance를 높여주기 때문에
- CNN 자체가 FCN 보다 성능이 나은 것도 원인
-
TPS tranformation이 가장 성능이 좋다.
2. Street View House Numbers

- 20만개 집 주소 표지판
- ST + Conv 여러 개를 사용
- ST-CNN Multi가 가장 좋은 성능 (속도는 6% 저하)
3. Fine-grained Classification

- Inception + BN
- 이미지 상에서 중요한 부분에 attention
- ST-CNN layer 4개 들어간 모델이 가장 성능이 좋다.
'Research' 카테고리의 다른 글
| 더욱 정교한 DeepFake: GANprintR (0) | 2020.05.31 |
|---|---|
| [CV Study] Learning Deep Features for Discriminative Localization (CVPR '16) (0) | 2020.05.31 |
| [CVPR 2020] Designing Network Design Spaces (1) | 2020.05.08 |
| [ASPLOS 2020] PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning (4) | 2020.05.03 |
| PyTorch IR에 관하여 (2) | 2020.03.05 |