
2020. 6. 11. 15:56ㆍResearch
Accuracy가 같다면 더 작을 모델일수록 (1) 서버 간의 커뮤니케이션을 줄일 수 있고, (2) 더 작은 대역폭(bandwidth)로도 서빙이 가능하고, (3) 한정된 메모리의 가속기에서 사용에 용이하다. SqueezeNet은 ImageNet에서 AlexNet과 동일한 수준의 accuracy를 유지하면서도 50배 더 적은 파라미터를 사용하고, compression 기법을 적용했을 때 AlexNet보다 510배 작은(<0.5MB) 용량을 가진다.
용어
1. CNN Microarchitecture
논문에서는 ResNet의 bottleneck block, GoogLeNet의 inception module과 같이 몇몇 op들이 모여서 이루어진 네트워크 building block을 microarchitecture라고 부른다.
2. CNN Macroarchitecture
Microarchitecture가 개별 레이어나 모듈을 지칭하는 반면, macroarchitecture는 전체 E2E CNN 모델 속에서 발견되는 구조를 의미한다. VGG에서 언급한 깊은 network의 중요성이라든지, ResNet에서 gradient vanishing을 막기 위한 shorcut connection이 그 예시라고 할 수 있다.
Design Strategies
SqueezeNet의 목표는 accuracy를 보존하면서 최대한 적은 파라미터를 사용하는 것이다. 이를 위해서 다음 3가지 디자인 방법론을 적용하였다. [전략 1], [전략 2]는 모델의 파라미터 수를 감소시키기 위한 방법에 해당하고 [전략 3]은 파라미터 수를 감소시키되 accuracy를 고려한 방법에 해당한다.
[전략 1]. 3x3 필터를 1x1로 교체
3x3 conv 대신에 1x1 conv를 사용하면 연산량이 9배 줄어들고, 9배 적은 파라미터를 갖게 된다.
[전략 2]. 3x3 convolution의 입력 채널 수를 감소
3x3 conv가 갖는 파라미터 수는 $(\text{input 채널 수}) \times (\text{필터 개수}) \times (3 * 3)$이다. (참고: 필터 개수 = output 채널 수) 따라서 input 채널 수를 줄이면 파라미터 수가 줄게 되는데, 뒤에서 살펴볼 squeeze layer를 통해서 3x3 conv로 들어가는 입력의 채널을 줄일 수 있다.
[전략 3]. 큰 activation map을 유지하기 위하여 downsampling은 네트워크의 후반부에서 수행
Activation map의 크기(HW)는 입력 데이터의 크기(e.g. 256 x 256 이미지)와 downsampling 비율에 의해서 결정된다. 일반적으로 CNN에서 downsampling은 convolution의 stride를 1보다 크게 잡거나, pooling을 통해서 이루어진다.
그런데 만약 downsampling이 네트워크의 초반부에 이루어진다면 그 여파로 네트워크 전체에서 작은 activation map을 갖게 되고, 모델의 성능을 저하시킬 수 있다. 따라서 accuracy와 더 작은 파라미터 두 가지 목적을 모두 달성하기 위해 downsampling은 오직 네트워크의 후반부에서만 수행한다.
Microarchitecture: The Fire Module

위의 그림은 SqueezeNet의 주요 building block(microarchitecture)인 fire module이다. 이 fire module에는 앞서 살펴본 3가지 디자인 전략중 [전략 1]과 [전략 2]의 아이디어가 담겨있다.
- [전략 1]: Squeeze layer와 expand layer에서 모두 1x1 conv가 사용되고 있고, 이는 파라미터 수를 줄이기 위함이다.
- [전략 2]: 하이퍼파라미터 $s_{1\times1}$은 squeeze layer에 있는 1x1 conv의 필터 수이고, $e_{1\times1}$은 expand layer의 1x1 conv 필터 수, $e_{3\times3}$은 expand layer의 3x3 conv 필터 수를 의미한다. Fire module에서는 $s_{1\times1} < e_{1\times1} + e_{3\times3}$을 만족하도록 하이퍼파라미터를 설정한다. (filter 수) = (output channel 수)이기 때문에 squeeze layer의 필터 수를 작게 잡아야 expand layer의 3x3 conv로 들어가는 input channel 수를 작게 만들어 모델 파라미터를 줄일 수 있다.
Macroarchitecuture: SqueezeNet
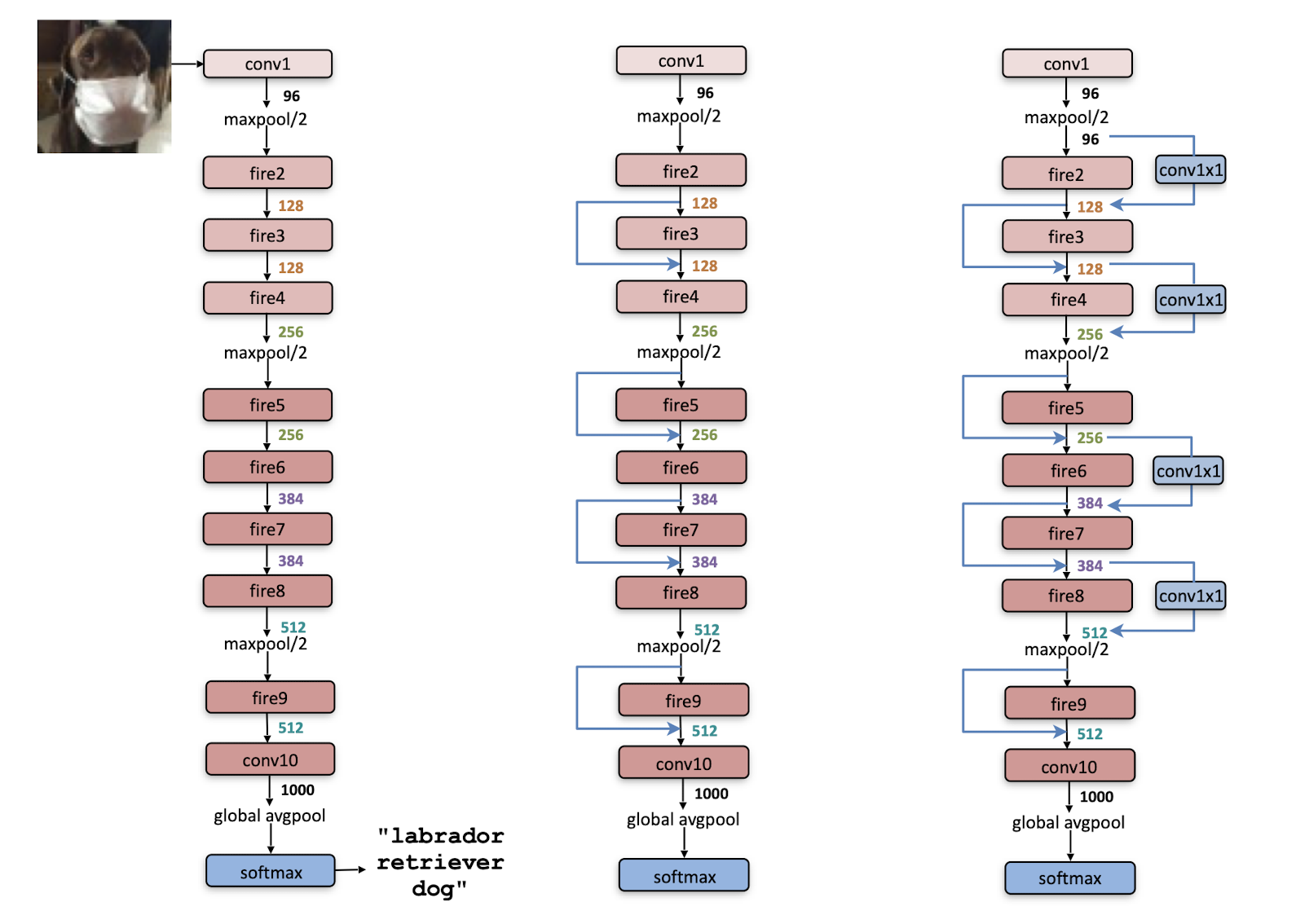
위 그림은 SqueezeNet의 전체 구조(macroarchitecture)를 보여준다. 보다시피 모델은 conv 1개 $\to$ fire module 8개 $\to$ conv 1개로 구성되어 있고, 모델의 후반부로 갈수록 fire module 당 필터 수를 늘리고 있다. 또한 conv1, fire4, fire8, conv10 뒤에선 2x2 max-pooling을 수행하여 downsampling을 한다. 이렇게 간헐적으로 pooling을 하는 것은 앞서 살펴본 [전략 3]을 염두에 둔 것이라 생각할 수 있다.
PyTorch Model Graph
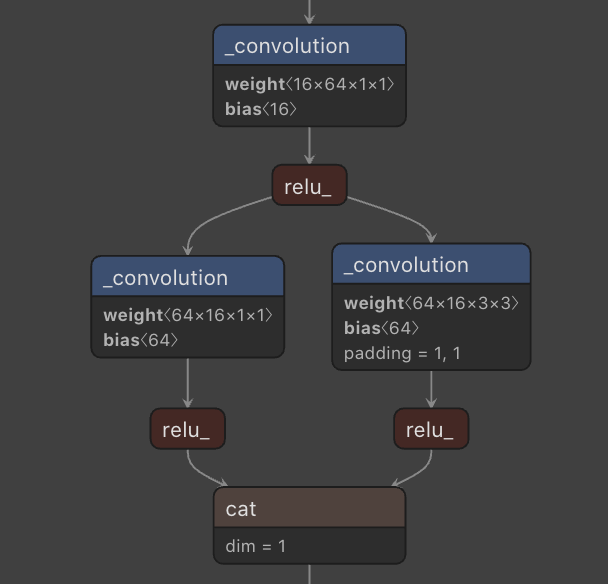
1. Fire Module
2. 모델 전체

'Research' 카테고리의 다른 글
| [CV Study] MobileNet: Efficient Convolutional Neural Networks for Mobile Vision Applications (1) | 2020.06.13 |
|---|---|
| [CV Study] GoogLeNet: Going Deeper With Convolutions (0) | 2020.06.13 |
| [CV Study] Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks (0) | 2020.06.11 |
| [CV Study] Generative Adversarial Nets (0) | 2020.06.11 |
| 더욱 정교한 DeepFake: GANprintR (0) | 2020.05.31 |