
2020. 4. 7. 00:56ㆍStudy
2008년 인텔은 AVX (Advanced Vector Extensions)라는 새로운 고성능 ISA를 발표한다. 이는 기존의 SSE (Streaming SIMD Extensions)에 포함된 많은 operation들을 지원함과 동시에 더 빠른 속도로 더 큰 덩어리(chunk)의 데이터를 처리할 수 있는 혁신적인 기술이었다.
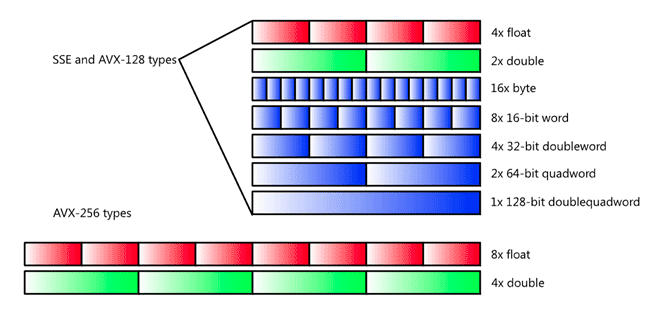
이 글에서는 intrinsic functions라고 불리는 특별한 C 함수들을 통해서 어떻게 AVX, AVX2를 이용할 수 있는지에 대해서 다룰 것이다.
AVX 명령은 mov, add와 같이 어셈블리 명령어에 해당한다. 예를 들어 vaddps라는 AVX 명령은 두 operand를 더해서 그 결과를 세번째 레지스터에 저장한다.
그렇다면 AVX 명령을 사용하기 위해선 어셈블리어로 코딩을 해야하는가? 다행스럽게도 그렇지는 않다. C/C++에서 AVX 명령을 직접 사용할 수 있도록 라이브러리가 갖추어져 있다! 예를 들어 앞서 언급한 vaddps와 같은 경우엔 _mm256_add_ps()라는 함수를 통해서 C/C++에서 사용할 수 있다. (마치 TF, PyTorch에서 파이썬은 사실상 API 역할만 하고 C++이 실제 executor 역할을 하듯이 C/C++ 함수는 assembly 코드를 호출하기 위한 API 역할을 한다.)
Vector Programming
AVX 명령은 작은 사이즈의 연산들을 각각 처리하는 것이 아니라 한번에 커다란 연산들의 chunk를 처리함으로써 어플리케이션의 속도를 비약적으로 향상시킨다. 이와 같은 커다란 크기의 데이터 덩어리를 일컬어 vector라고 하며, AVX vecotr는 256 비트의 데이터까지 담아낼 수 있다. 따라서 일반적인 AVX vector는 4개의 double 타입 데이터 (4 x 64 = 256), 8개의 float 타입 데이터 (8 x 32 = 256), 8개의 int 데이터 (8 x 32 = 256)를 표현하는데 사용될 수 있다.
다음 예시는 AVX/AVX2 연산이 왜 효율적인지 잘 보여준다. 바로 아래의 코드는 크기 8의 배열 d에 동일한 인덱스에 해당하는 a와 b의 원소를 곱하고, 그 결과에 같은 인덱스의 c의 원소를 더하여 저장하는 작업을 하고 있다.
multiply_and_add(const float* a, const float* b, const float* c, float* d) {
for(int i=0; i<8; i++) {
d[i] = a[i] * b[i];
d[i] = d[i] + c[i];
}
}
위의 코드를 AVX2 명령어 함수를 사용해서 바꾼다면 다음과 같이 단 한 줄짜리 코드로 만들 수 있다. _mm256_fmadd_ps() 함수는 AVX2 intrinsic 함수 중 하나로, vfmadd132ps, vfmadd213ps, vfmadd231ps 세 가지 명령을 순차적으로 실행한다. 비록 3개의 명령을 실행하긴하지만 loop를 돌며 계산하는 앞의 코드와 비교했을 때 훨씬 좋은 성능을 낼 수 있다.
__m256 multiply_and_add(__m256 a, __m256 b, __m256c) {
return _mm256_fmadd_ps(a, b, c);
}
AVX Programming의 기초
1. Data Types
몇몇 intrinsic 함수들은 int나 float과 같은 기존 데이터 타입과 호환이 되지만 대부분의 함수들은 AVX/AVX2에 특화된 데이터 타입을 사용한다. 가장 주요한 데이터 타입 6가지는 다음과 같다.
| 자료형 | 비트 수 | 설명 |
| __m128 | 128 | 4 floats |
| __m128d | 128 | 2 doubles |
| __m128i | 128 | integers |
| __m256 | 256 | 8 floats |
| __m256d | 256 | 4 doubles |
| __m256i | 256 | integers |
위에서 볼 수 있다시피 각각의 타입명은 '__m' + '비트 수'와 같이 표현된다. AVX512의 경우엔 512 비트 벡터 타입까지도 지원하는데, 이는 __m512로 시작한다.
__m128i와 __m256i는 i가 뒤에 붙어 있어서 int형만을 포함해야할 것 같이 보이지만 char, short, unsigned long long과 같은 여러 정수형 자료형을 포함할 수 있다.
2. Function Naming Convention
AVX/AVX2 함수 이름을 마주쳤을 때 첫 인상은 뭔가 사용하기 싫은 불쾌한? 느낌이 아닐까 싶다. 하지만 생각보다 깔끔하고 규칙적인 naming convention을 따르고 있다. generic AVX/AVX2 intrinsic 함수는 다음과 같다.
__mm<bit_width>_<name>_<data_type>
1. <bit_width>는 return value에 해당하는 vector의 사이즈를 나타낸다.
2. <name>은 operator의 이름을 나타낸다.
3. <data_type>은 함수의 주요 인자의 데이터 타입을 나타낸다.
다음은 <data_type>에 들어갈 데이터 타입의 종류이다.
- ps: floats를 포함하는 벡터
- pd: doubles를 포함하는 벡터
- epi8/epi16/epi32/epi64: 8, 16, 32, 64 비트의 signed integer를 포함하는 벡터
- epu8/epu16/epu32/epu64: 8, 16, 32, 64 비트의 unsigned integer를 포함하는 벡터
- si128/si256: 타입이 명시되지 않은 128, 256 비트의 벡터
- m128/m128i/m128d/m256/m256i/m256d: 리턴 벡터의 타입과 인풋 벡터타입이 다를 경우
3. AVX 어플리케이션 만들기
AVX intrinsics를 사용하기 위해서 해야할 일은 딱 하나. immintin.h 헤더를 include하는 것이다. 다음 코드는 실제로 동작하는 간단한 AVX 어플리케이션의 예시이다.
/* 파일명: hello_avx.c */
#include <immintrin.h>
#include <stdio.h>
int main() {
/* Initialize the two argument vectors */
__m256 evens = _mm256_set_ps(2.0, 4.0, 6.0, 8.0, 10.0, 12.0, 14.0, 16.0);
__m256 odds = _mm256_set_ps(1.0, 3.0, 5.0, 7.0, 9.0, 11.0, 13.0, 15.0);
/* Compute the difference between the two vectors */
__m256 result = _mm256_sub_ps(evens, odds);
/* Display the elements of the result vector */
float* f = (float*)&result;
printf("%f %f %f %f %f %f %f %f\n",
f[0], f[1], f[2], f[3], f[4], f[5], f[6], f[7]);
return 0;
}
위의 어플리케이션(hello_avx.c)를 컴파일 하기 위해서는 추가적인 flag option을 주어야 한다. 가장 흔히 사용하는 gcc 컴파일러의 경우엔 -mavx를 옵션으로 주면된다.
gcc -mavx -o hello_avx hello_avx.c
만약 AVX가 아니라 AVX2를 사용한다면 -mavx가 아니라 -mavx2 옵션을 주면되고, FMA을 사용한다면 -mfma 옵션을 주면된다.
Initialization Intrinsics
AVX vector 연산을 사용하기 이전에 먼저 해야할 일은 당연히 vector를 실제 데이터로 채우는 일이다. vector는 두 가지 방식으로 초기화 될 수 있는데, 하나는 scalar 값으로 초기화하는 것이고, 다른 하나는 메모리부터 로드한 데이터로 초기화하는 것이다. 하나씩 살펴보도록 하자.
1. 스칼라 값으로 벡터 초기화하기
AVX는 256 비트 벡터에 한 개 이상의 값을 넣을 수 있는 API를 제공한다. 다음 표에서는 초기화에 사용되는 함수들과 각각에 대한 설명이 있으니 참고하길 바란다.
| 함수명 | 설명 |
| __mm256_setzero_ps / pd | 0으로 채워진 floating point 벡터를 반환 |
| __mm256_setzero_si256 | 각 바이트가 0으로 초기화된 int 벡터를 반환 |
| __mm256_set1_ps / pd | 벡터를 floating point 값으로 채움 |
| __mm256_set1_epi8 / epi16 / epi32 / epi64 | 벡터를 int 값으로 채움 |
| __mm256_set_ps / pd | 벡터를 8개의 floats 또는 4개의 doubles로 채움 |
| __mm256_set_epi8 / epi16 / epi32 / epi64 | 벡터를 주어진 int 값으로 초기화 |
| __mm256_set_m128 / m128d / m128i | 256 비트 크기의 벡터를 2개의 128 비트 크기의 벡터로 초기화 |
| __mm256_setr_ps / pd | 8개의 floats / 4개의 doubles를 가지고 벡터를 역순으로 초기화한다 |
| __mm256_setr_epi8 / epi16 / epi32 / epi64 | 주어진 정수값들로 벡터를 역순으로 초기화 |
아주 간단한 사용 예시를 하나만 들자면 다음과 같다. 다음 코드는 32bit integer value 8개로 256bit 벡터를 초기화하고 출력한다.
__m256i int_vector = _mm256_setr_epi32(1, 2, 3, 4, 5, 6, 7, 8);
int *ptr = (int*)&int_vector;
printf("%d %d %d %d %d %d %d %d\n", ptr[0], ptr[1], ptr[2], ptr[3], ptr[4], ptr[5], ptr[6], ptr[7]);
2. 메모리에서 로드한 데이터로 벡터 초기화하기
앞에서와 같이 스칼라 값을 인자로 주어서 벡터를 초기화할 수도 있고, malloc한 메모리 데이터를 인자로 주어 벡터를 초기화할 수도 있다.
| 함수명 | 설명 |
| _mm256_load_ps / pd | 인자로 전달된 메모리 주소로부터 fp 벡터를 로드 |
| _mm256_load_si256 | 인자로 전달된 메모리 주소로부터 int 벡터를 로드 |
| _mm256_loadu_ps / pd | 인자로 전달된 "아직 할당되지 않은" 메모리 주소로부터 fp 벡터를 로드 |
| _mm256_loadu_si256 | 인자로 전달된 "아직 할당되지 않은" 메모리 주소로부터 int 벡터를 로드 |
| _mm_maskload_ps / ps | 128 / 256 비트의 일부를 로드 |
| _mm256_maskload_ps / pd | mask에 따라서 fp 벡터를 로드 |
| [AVX2 함수] _mm_maskload_epi32 / 64 | 128 / 256 비트의 일부를 로드 |
| [AVX2 함수] _mm256_maskload_epi32 / 64 | mask에 따라서 fp 벡터를 로드 |
메모리에서 벡터로 데이터를 로드하는 경우엔 메모리 alignment가 특히나 중요하다. _mm256_load_ 로 시작하는 intrinsic 함수들은 반드시 32 바이트 단위로 align된 데이터만을 인자로 받을 수 있다.
float* aligned_floats = (float*)aligned_alloc(32, 64 * sizeof(float));
... Initialize data ...
__m256 vec = _mm256_load_ps(aligned_floats);
만약 aligned_alloc을 쓰지 않고 malloc으로 메모리 공간을 할당한 뒤 그 주소를 가지고 _mm256_load_*를 사용하면 segmentation fault가 발생한다. alignment가 맞춰지지 않은 경우에는 _m256_loadu_*를 사용하면 된다.
float* unaligned_floats = (float*)malloc(64 * sizeof(float));
... Initialize data ...
__m256 vec = _mm256_loadu_ps(unaligned_floats);
위의 표에서 mask라는 단어가 포함된 함수는 alignment가 맞지 않은 데이터를 마스킹하여 호환 가능하도록 만들어주는 역할을 한다. _masklaod_가 들어간 함수는 인자로 (1) 로드할 메모리 주소 (2) mask 비트 패턴을 받는데 mask 비트패턴의 highest bit이 1이면 해당 부분의 메모리는 로드가 되고, 0이면 로드되지 않는다. 다음 예시를 살펴보면 mask 변수에 _mm256_setr_epit32()를 할 때 마지막 3개 인자(3, 5, 8)는 MSB가 0이고 그 앞의 5개 인자는 음수이므로 MSB가 1이다. 이렇게 할당된 mask를 가지고 _mm256_maskload_epi32를 호출하면 {100, 200, 300, 400, 500, 600, 700, 800} 중에 앞의 5개 원소까지는 그 값 그대로 할당이 되고, 그 뒤의 3개 원소는 0으로 세팅된다.
#include <immintrin.h>
#include <stdio.h>
int main() {
int i;
int int_array[8] = {100, 200, 300, 400, 500, 600, 700, 800};
/* Initialize the mask vector */
__m256i mask = _mm256_setr_epi32(-20, -72, -48, -9, -100, 3, 5, 8);
/* Selectively load data into the vector */
__m256i result = _mm256_maskload_epi32(int_array, mask);
/* Display the elements of the result vector */
int* res = (int*)&result;
printf("%d %d %d %d %d %d %d %d\n",
res[0], res[1], res[2], res[3], res[4], res[5], res[6], res[7]);
return 0;
}
/*****************************
실행결과:
100 200 300 400 500 0 0 0
*****************************/
Arithmetic Intrinsic
AVX/AVX2에는 여러 가지 벡터 연산 함수들을 제공하지만 이 글에서는 간단히 사칙연산만을 살펴보도록 하겠다. 사칙연산을 살펴본 이후에는 FMA(Fused Multiply and Add) 익스텐션에 대해서도 간단히 알아볼 것이다.
1. Addition & Subtraction
| 함수명 | 설명 |
| _mm256_add_ps / pd | 두 개의 FP 벡터를 더한다. |
| _mm256_sub_ps / pd | 두 개의 FP 벡터의 뺄셈 |
| [AVX2] _mm256_add_epi8 / 16 / 32 / 64 | 두 개의 정수형 벡터를 더한다. |
| [AVX2] _mm256_sub_epi8 / 16 / 32 / 64 | 두 개의 정수형 벡터의 뺄셈 |
| [AVX2] _mm256_adds_epi8 / 16 | 메모리 초과(saturation)를 고려한 두 정수의 덧셈 |
| [AVX2] _mm256_subs_epi8 / 16 | 메모리 초과를 고려한 두 정수의 뺄셈 |
| _mm256_hadd_ps / pd | 두 FP 벡터를 수평으로 더한다. |
| _mm256_hsub_ps / pd | 두 FP 벡터 간의 뺄셈을 수평으로(horizontally) 수행 |
| [AVX2] _mm256_hadd_epi16 / 32 | 두 정수 벡터를 수평으로 더한다. |
| [AVX2] _mm256_hsub_epi16 / 32 | 두 정수 간의 뺄셈으로 수평으로 수행 |
| [AVX2] _mm256_hadds_epi16 | 메모리 초과를 고려하여 두 정수를 수평으로 더한다. |
| [AVX2] _mm256_hsubs_epi16 | 메모리 초과를 고려하여 두 정수간의 뺄셈을 수평으로 수행 |
| _mm256_addsub_ps / pd | 두 개의 FP를 더하고 뺀다. |
위의 표에서는 가장 많이 쓰이는 덧셈 / 뺄셈 벡터 연산 함수들을 보여준다. 'adds', 'subs' 같이 's'가 붙은 것들은 saturation, 즉 연산의 결과값이 벡터가 저장 가능한 메모리 크기보다 더 큰 메모리 크기를 요구할 경우에, saturation을 고려하여 저장 가능한 최소/최대의 값을 저장한다. 만약 saturation을 고려하지 않는 일반 add, sub 함수를 사용했는데 saturation이 발생한 경우, 이를 그냥 무시한다. 예를 들어, signed byte를 담을 수 있는 어떤 벡터(각 원소의 최대 값은 127)가 있을 때, 만약 98 + 85 = 183이라는 연산이 발생하여 overflow가 생긴 경우를 생각해보자. 이 경우 _mm256_add_epi8 함수는 saturation을 그냥 무시하고, 값을 저장한다. 그러면 183의 bit 값인 0xB7이 저장되는데 이를 signed로 해석하면 183이 아니라 -73이라는 원치 않는 값이 저장된다. 따라서 overflow 상황에 대처할 수 있도록 _mm256_adds_epi8 함수를 사용해야하는데, 이 경우엔 메모리 공간상 저장 가능한 최대 signed 값인 127(0x7F)이 저장된다. 이와 반대로 underflow가 발생한 경우에는 saturation을 고려하는 함수를 사용한다면 표현 가능한 최소값이 저장된다.
한편, _hadd_, _hsub_와 같이 'h'가 들어간 함수들이 보이는데, 이는 수평으로(horizontally) 연산을 하는 함수이다. 즉 같은 인덱스에 해당 하는 서로 다른 벡터의 원소끼리 더하고 빼는 것이 아니라 벡터 내부의 인접한 원소끼리 연산을 수행한다. 다음 그림은 _mm256_hadd_pd 함수가 어떻게 동작하는지 보여준다. 이런 이상한 연산을 하는 함수가 어디에 쓰일까 싶을 수도 있지만, complex number 계산에 매우 유용하다.

표의 가장 마지막에 있는 _mm256_addsub_ps / pd 함수는 번갈아 가면서 FP 벡터에 대해 뺄셈, 덧셈을 수행하는 함수이다. 즉, 짝수 인덱스에 해당하는 원소끼리는 뺄셈을 하고, 홀수 인덱스에 해당하는 원소끼리는 덧셈을 수행한다. 예를 들어 vec_a = {0.1, 0.2, 0.3, 0.4}이고 vec_b = {0.5, 0.6, 0.7, 0.8}이라면, _mm256_addsub_pd(vec_a, vec_b)의 결과 벡터는 {-0.4, 0.8, -0.4, 1.2}가 된다.
2. Multiplication & Division
| 함수명 | 설명 |
| _mm256_mul_ps / pd | 두 FP 벡터를 곱한다. |
| [AVX2] _mm256_mul_epi32 | 두 32비트 정수 벡터의 가장 낮은 4개 인덱스의 원소들을 곱한다. |
| [AVX2] _mm256_mul_epu32 | 두 32비트 unsigned 정수 벡터의 가장 낮은 4개 인덱스의 원소들을 곱한다. |
| [AVX2] _mm256_mullo_epi16 / 32 | 두 정수 벡터를 곱하고 낮은 인덱스 부분에 해당하는 전체 원소의 절반을 메모리에 저장한다. |
| [AVX2] _mm256_mulhi_epi16 / 32 | 두 정수 벡터를 곱하고 높은 인덱스 부분에 해당하는 전체 원소의 절반을 메모리에 저장한다. |
| [AVX2] _mm256_mulhrs_epi16 | 16비트 원소를 갖는 두 개의 정수 벡터를 곱해서 32비트 원소를 갖는 벡터를 출력한다. |
| _mm256_div_ps / pd | 두 FP 벡터의 나눗셈을 수행한다. |
Reference: https://www.codeproject.com/Articles/874396/Crunching-Numbers-with-AVX-and-AVX
Crunching Numbers with AVX and AVX2
This article explains how to perform mathematical SIMD processing in C/C++ with Intel's Advanced Vector Extensions (AVX) intrinsic functions.
www.codeproject.com
'Study' 카테고리의 다른 글
| OpenCL에서 효율적인 행렬곱(matrix multiplication) 수행 (2) | 2020.05.10 |
|---|---|
| C와 Python에서의 음수 나눗셈에 관하여 (0) | 2020.05.05 |