
2020. 6. 2. 17:46ㆍOperating System
디스크 구조
- 디스크는 여러개의 block들로 구성되어 있으며 block 단위로 allocate, free한다.
- 또한 virtual memory와 마찬가지로 logical disk - physical disk의 virtualization이 존재한다.
어떻게 공간 할당을 할 것인가?
공간할당 방법 디자인 시 고려사항: fragmentation, access performance, meta-data overhead
1. Contiguous Allocation

장점
- sequential access 시 매우 좋음.
- 단순함
- meta-data 오버헤드 적음
단점
- External fragmentation 최악
2. Extend-based

-
파일 하나당 여러개의 연속적인 space를 할당한다.
-
offset + size를 헤더에 저장
-
1번 방식에서 external frag를 보완하는 정도
3. Linked

장점
-
External fragmentation 없다.
단점
-
random access가 매우 안 좋다.
-
block 마다 next block을 가리키는 포인터가 필요하기 때문에 오버헤드가 있다.
4. FAT (File Allocation Table)

-
3번과 같은 linked allocation인데 실제 데이터가 아니라 FAT를 연결 리스트로 만들어서 관리한다.
-
disk에서 read를 두번(FAT, 실제 data) 해야한다는 단점이 있으나 FAT를 메모리에 캐싱 하면 해결가능하다.
5. Indexed

모든 데이터 블록들을 fixed size array로 다룬다.
장점
-
External fragmentaion이 없다.
-
Index를 통해서 random access가 가능하다.
단점
-
사용하지 않는 공간에 대해서도 index를 기억해야하기 때문에 metadata 오버헤드가 크다.
6. Multi-Level Indexed
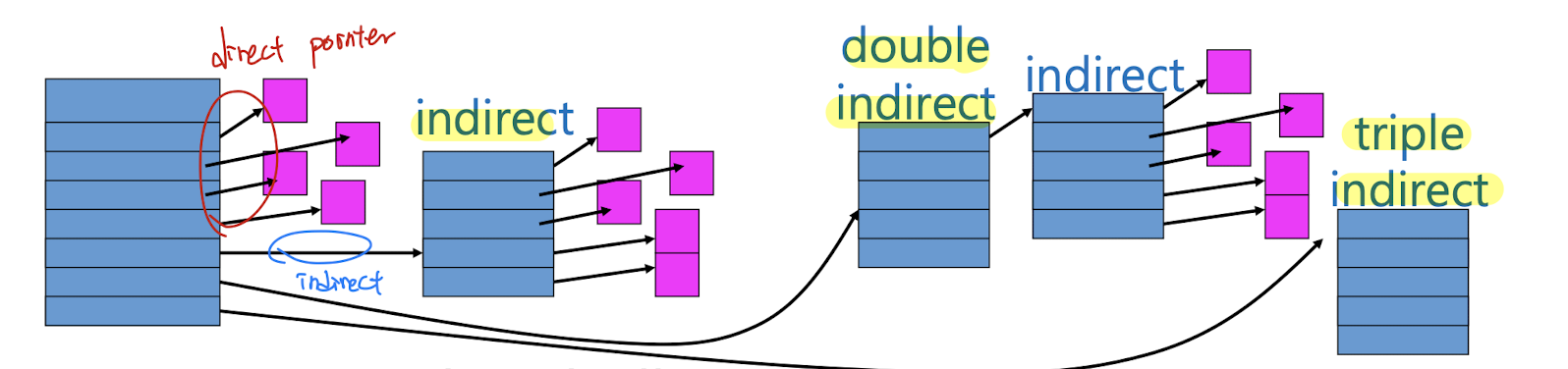
Memory에서의 multi-level page table과 완전히 동일한 원리이다. 마찬가지로 time-space trade-off가 존재한다.
-
각 inode의 direct pointer와 indirect pointer의 개수는 고정되어 있다.
-
우선 direct로 할당되었다가 다 차면 indirect를 통해 확장한다.
- indirect pointer는 data block을 가리킨다. (1024개의 블록만큼 확장 가능)
- double indirect pointer는 indirect pointer를 가리킨다. (1024 x 1024개의 블록만큼 확장 가능)
- triple indirect pointer는 double indirect pointer를 가리킨다. (1024 x 1024 x 1024개의 블록만큼 확장 가능)
장점
-
불필요한 포인터에 대해서 공간을 낭비하지 않는다.
단점
-
Address 계산을 위해서 indirect block을 읽는 경우 2번 이상의 read를 하게된다. indirection level이 깊어질 수록 추가적인 read의 양이 많아지지만 메모리 캐싱을 통해 해결가능하다.
On-disk 구조
데이터 블록과 inode
여기에서 각각의 block은 4KB라고 가정한다.
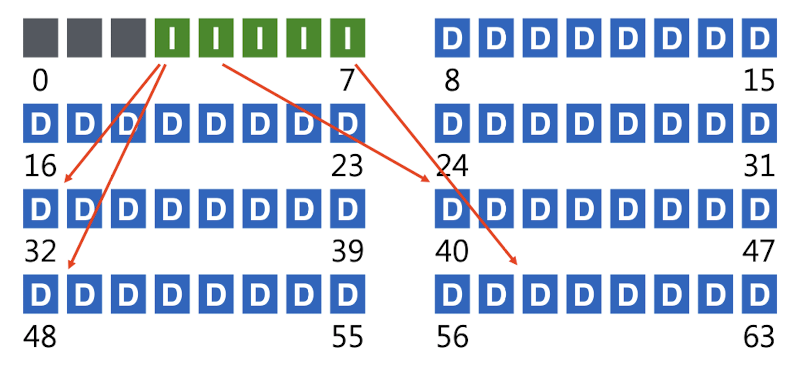
위에서 각 네모 한개는 4KB 크기의 블록에 해당하고, 회색 블록은 empty 블록, 초록색 블록은 inode들이 들어간 블록, 파란색 블록은 data 블록에 해당한다. 만약 inode 한 개의 크기가 256B라고 가정하면, 위의 그림에서 초록색 블록 하나에는 총 16개의 inode가 들어간다. 아래의 그림은 4KB 블록 하나에 16개의 inode가 들어간 모습을 보여준다.

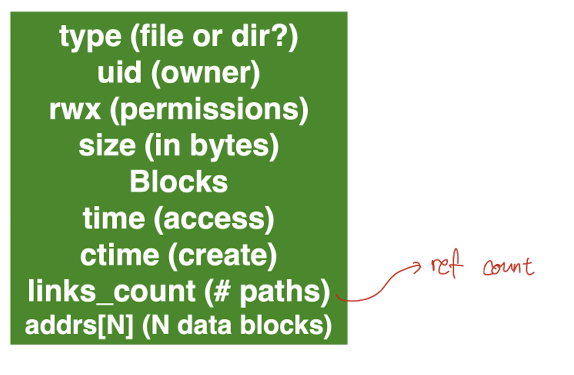
위의 그림에서 빨간 동그라미 쳐진 inode 한 개를 더욱 확대해서 보면 다음과 같은 구조를 가졌다. 만약 pointer의 크기가 4B라면 inode 한 개에는 총 256/4 = 64개의 주소를 저장할 수 있다. 이는 inode 한개로 총 64개의 data 블록을 참조할 수 있다는 의미이며, data 블록 하나당 4KB의 크기를 가지므로 총 64 x 4KB = 256KB 크기의 파일을 참조할 수 있다는 뜻이다. 하지만 실제로는 아래의 그림과 같이 inode에는 data block pointer 외에 여러 metadata(type, uid, size, link_cnt, time, generation 등)가 저장되므로 그보다는 더 적은 양의 파일이 참조 가능하다.
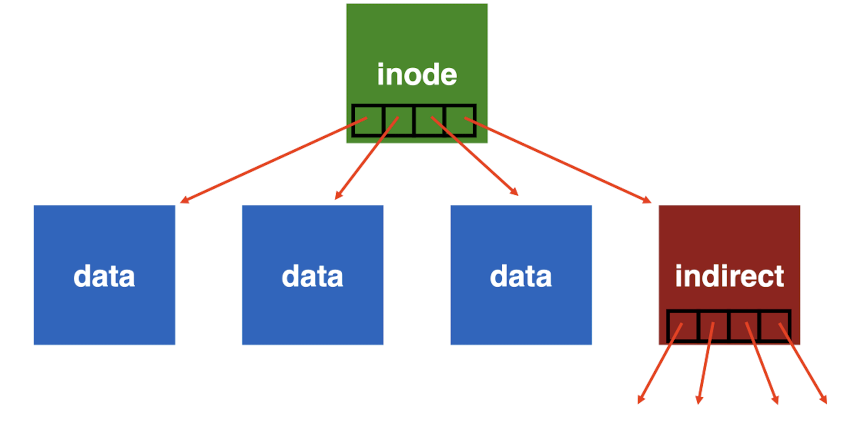
만약 위에서 살펴본 multi-level file system이라면 어떨까?
아래의 그림과 같이 inode가 참조하는 한개의 block은 indirect pointer들로 구성하여 하나의 inode가 더 많은 block을 참조하도록 만들 수 있다.
Bitmap & SuperBlock
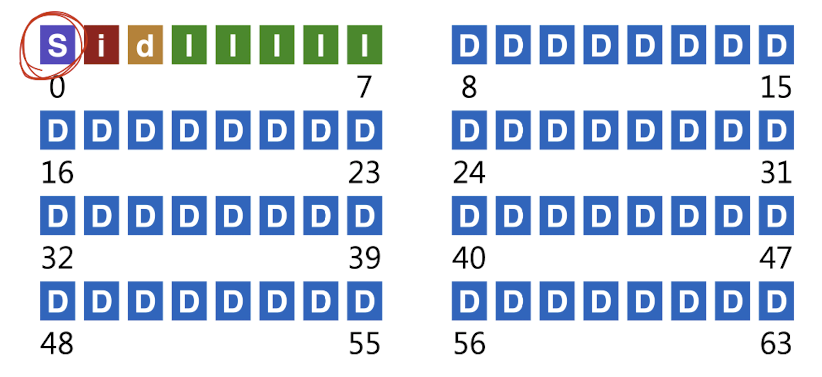
위의 그림과 같이 4KB 블록 하나는 inode bitmap으로, 또 다른 하나의 4KB 블록은 data bitmap으로 사용할 수 있다. 또한 가장 첫 번째 블록은 superblock으로 사용한다. 각각의 블록의 기능은 다음과 같다.
- data bitmap
- 어떤 data block이 free한지 확인
- inode bitmap
- 어떤 inode block이 free한지 확인
- superblock
- FS에 대한 전체적인 정보, metadata
- block size
- inode가 block에 몇개인가
- free한 공간은 얼마인가...
- FS에 대한 전체적인 정보, metadata
Disk Operations
앞에서 특정 파일을 수정하면 해당 파일 하나에 대해서만 정보가 바뀌는 것이 아니라 부모 디렉토리에 있는 파일들에 대해서도 read, write가 이루어진다고 하였다. 실제 예시들을 통해 그 과정을 자세히 살펴보자.
1. 파일 생성 예시
다음과 같은 명령을 수행한다고 해보자
$ create /foo/bar이 명령을 수행하면 다음과 같은 일련의 과정이 실행된다. (R은 read, W는 write를 의미한다.)
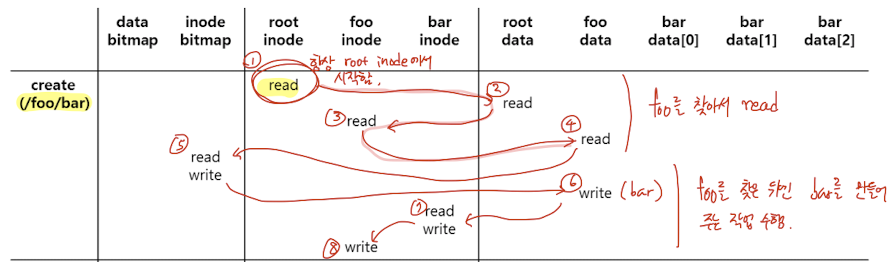
- R root inode
- R root data (find foo inode #)
- R foo inode
- R foo data
- R inode bitmap
- W inode bitmap (새로운 inode가 추가됨을 기록)
- W foo data (bar inode를 추가)
- R bar inode
- W bar inode
- W foo inode
1~4번까지의 과정은 root에서 시작해서 foo/ 디렉토리를 찾아가는 과정이다. (root 데이터 블록을 읽고나서 foo/의 inode를 읽는 것은 상위 폴더의 데이터 블록에 하위 path file을 참조하는 inode가 저장되어 있기 때문이다.)
5번부터는 foo/의 하위에 bar 파일을 반들어 주는 과정이다. 새로운 파일이 생성되므로 inode bitmap을 수정(어떤 inode가 사용중인지 표시)하고, foo의 data => bar의 inode => foo의 inode 순으로 write를 한다. 이 때 write 순서에 주목할 필요가 있는데, data에 먼저 write를 하고, 마지막에 inode를 write해야 fault-tolerant하다.
2. write
$ write /foo/bar "something"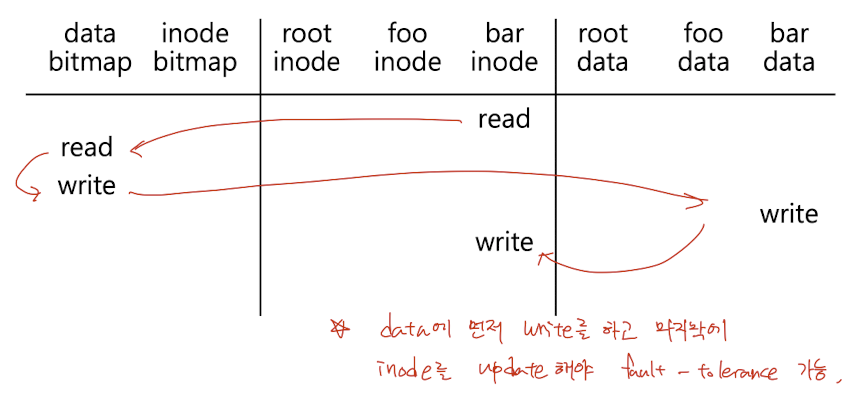
앞에서 말했듯이, data block을 inode보다 먼저 업데이트해야 fault-tolerant하다.
- data bitmap을 읽고
- data bitmap에 쓰고 (업데이트)
bardata에 쓰고barinode에 쓰고
3. open
root inode에서 부터 열고자하는 파일의 inode까지 차례대로 읽어나가면 된다.
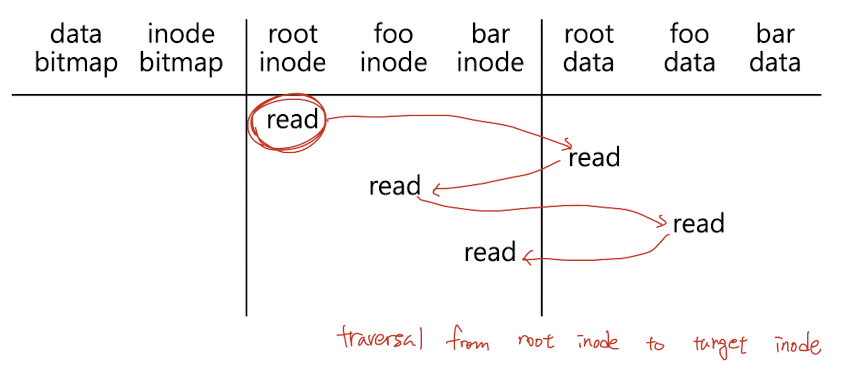
4. read
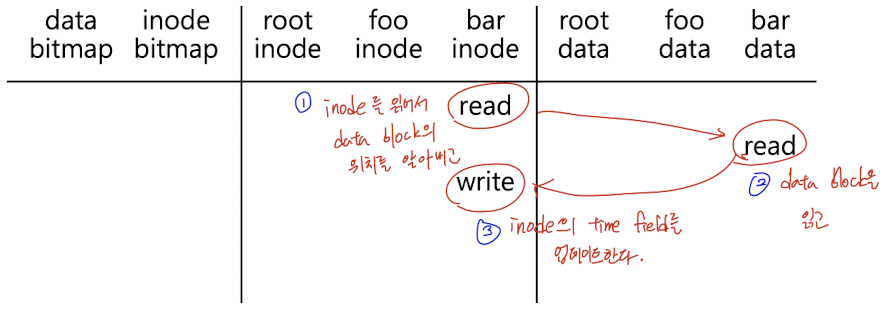
inode는 실제 데이터가 저장된 data block을 가리킴과 동시에 최근 접근 시간(latest access time)과 같은 metadata 정보도 관리한다. 다라서 파일에 read를 할 경우에 실제 데이터를 변경하지 않더라도 metadata가 새로 쓰이기 때문에 inode에 write가 이루어진다.
Caching & Buffering
위에서 살펴보았듯이 접근하려는 파일의 path depth가 깊을수록 접근 시간이 증가한다. 이를 해결하기 위해서 DRAM에 캐싱을 하는 것이고, 자주 쓰이는 블록은 locality로 인해 거의 메모리 위에 올라와 있게 된다.
캐싱을 통해서 데이터 접근 시간을 줄일 수 있지만 write traffic을 줄이지는 못한다. Write traffic은 버퍼링을 통해서 효과적으로 줄일 수 있다. 즉 디스크에 쓸 내용을 메모리에 모아두었다가 한번에 write through하는 식이다.
fsync 함수를 통해 강제로 메모리에 저장된 데이터를 디스크로 flush할 수도 있다. (하지만 이는 disk driver에 따라 의도대로 flush 되지 않을 수 있다.)
'Operating System' 카테고리의 다른 글
| [Operating System] Crash Consistency (0) | 2020.06.03 |
|---|---|
| [Operating System] FFS (Fast File System) (0) | 2020.06.03 |
| [Operating System] File System API (0) | 2020.06.02 |
| [Operating System] RAID (Redundant Array of Inexpensive Disk) (0) | 2020.06.02 |
| [Operating System] I/O Devices (0) | 2020.06.02 |