
2020. 6. 3. 01:07ㆍOperating System
Crash Consistency란?
- Crash가 발생하더라도 복구 가능하도록 대비를 하는 것. (옛날 데이터만 있거나, 새로운 데이터만 있거나 둘 중 하나의 상태여야만 한다. 둘 다 반반 씩 있는 경우는 절대 존재해서는 안 된다.)
- Write 시에 inode, bitmap, data block이 모두 올바르게 atomic transaction으로 업데이트 되어야 한다. 예를 들어 append를 하는 경우에, data bitmap, inode, data block 모두가 수정이 되어야 하나의 append 연산이 완료되었다고 볼 수 있다.
- Crash가 발생했을 때 이전 상태로 돌아가거나 업데이트 하려던 상태로 복구 가능해야 한다.
가능한 Crash 시나리오
참고) 디스크에서는 하나의 sector에 대해서 atomic write가 가능하도록 보장을 해주지만 서로 떨어진 sector에 대해서는 atomicity를 보장하지 못한다.
Write가 성공했다고 말하려면 다음 세 가지 정보가 모두 disk에 온전히 write 되어야 한다. 즉, 다음의 세 가지 정보가 모두 쓰여지던지, 아무 것도 쓰여지지 않던지 둘 중의 하나의 상황만 존재해야 한다.
- Inode
- Data Bitmap
- Data Block
아래에서 파란색 표시된 케이스는 문제가 없는 케이스고 빨간 색 표시된 케이스는 문제가 있는 케이스이다.
1개만 성공
- data block만 성공: 데이터를 썼다는 사실이 inode나 bitmap에 반영이 안 되었으므로 그냥 쓰레기 값 취급을 하면 되어서 문제가 없음
- inode만 성공: 데이터를 썼다고 하는데 실제로 새로운 값이 쓰이지 않았으므로 에러 (point to garbage)
- Bitmap만 성공: bitmap은 특정 블록에 쓰였다고 표시되었으나 inode는 그를 가리키지 않는 상황이므로 이상한 값을 읽지는 않겠으나, bitmap에 따라서 해당 블록에는 write를 하지 않을 것이기 때문에 disk 공간의 낭비가 발생 (lost block)
2개만 성공
- inode와 bitmap만 성공: 쓰레기 값이 들어있는 data block에 값이 있다고 가리키고 있으므로 에러. (point to garbage)
- inode와 data block만 성공: data block에 write를 하는 경우에 bitmap을 참조하는데 bitmap에서 data가 할당되지 않았다고 표시 되어있으면 실제로 할당이 되었음에도 불구하고 overwrite를 해버릴 수 있음. (another file may use)
- bitmap과 data block만 성공: bitmap은 data가 있다고 표시를 하고 있고 실제로 data block에도 데이터가 있는 상황이지만 inode에서 data block을 가리키는 포인터가 없어서 data를 찾을 수가 없음 (lost block)
해결 방안
Data Redundancy
해결 방안은 결국 백업을 위해서 추가적으로 데이터를 사용하는 것밖에 없다.
- 장점: Reliablility(RAID-1 mirroring, RAID-5 parity, FFS superblock에 해당)와 performance(RAID-1 mirroring, FFS summary block, FFS bitmap에 해당)를 증가시킬 수 있음
- 단점: Capcity와 consistency를 저하
- Redundant block 역시 업데이트의 대상인데, power loss, kernel panic, reboot 등과 같은 crash, interrupt 상황에서 consistent하게 업데이트 되지 않을 수 있음.
해결방안1: FSCK (File System Checker)
- 일관성 없는 데이터를 찾아내고 그것을 수정(하려고 시도)하는 unix 도구
- fsck에서 하는 일은 data와 metadata 간의 일관성을 유지해주는 일
- Crash가 발생하면 전체 디스크를 스캔하고 문제가 있는 부분을 발견하면 (가능한 경우엔) 고치거나, 그 사실을 알림.
fsck는 ext2, ext4와 같은 fs의 특성에 따라서 다르게 만들어져야 함
1.1. 체크 대상
- Superblock: file system size와 그에 할당된 block의 개수가 부합하는가. 의심가는 superblock을 찾아내고 문제가 있으면 copy본으로 대체함.
- Free Block: inode, indirect / double indirect block을 스캐닝한다. Inode 포인터가 가리키는 데이터가 bitmap에서도 제대로 마킹 되어 있는지 확인한다.
- Inode state: inode의 type 체킹. corruption 체킹
- Inode link: 전체 디렉토리 트리를 순회하면서 link count가 올바른지 확인.
- 만약에 inode에 적힌 ref count와 다르다면 적절한 action이 취해져야함
- Inode 상으로는 데이터가 할당 되어 있는 것으로 보이는데 해당 파일을 담고 있는 디렉토리가 없는 경우엔 lock&found 디렉토리로 이동된다.
- Duplicate pointer(두개의 inode가 같은 블록을 가리킴)를 체크하여 지우거나 복사본을 만들거나
- Bad Blocks: valid range 밖의 무언가를 가리키는 경우 (그냥 해당 포인터를 지우는 수밖에 없음)
- Directory Check: fsck은 user file의 실제 내용까지 이해하지는 못하고 각각의 디렉토리가 file system의 기본 포멧에 맞는지, meta-data에 부합하는지 체크 할 뿐
- ex) dentry 내의 inode들이 잘 할당되어 있는가.
.,..이 가장 앞에 있는가. 전체 fs 구조에서 directory의 link가 올바른가.
- ex) dentry 내의 inode들이 잘 할당되어 있는가.
1.2. Fix 예시
- 두 개의 dentry가 참조하는 inode의 count가 1인 경우
- count를 2로 수정
- Inode의 count가 1인데 어떤 data block도 해당 inode에 의해 참조되지 않는 경우
- dentry 하나를 연결해주고 lost&found 폴더로 이동
- Data bitmap이 잘못된 경우
- 그냥 inode와 block에 부합하게 수정하면 됨
- 두 개의 inode가 동일한 data block을 가리킨다면?
- data block의 copy를 만들고 inode 중 한개는 그것을 가리키도록 함
- Bad pointer (out of range)
- 삭제할 수밖에 없음
1.3. fsck의 문제점
- fsck의 근본적인 문제는 전체 디렉토리를 스캔하기 때문에 시간이 매우 많이 걸린다는 점! 디스크의 크기가 커질 수록 시간이 더욱 많이 걸리기 때문에 다른 방법이 필요함. (600GB - 70분)
- 확실하게 fix를 할 수 있는 경우가 많지 않음. 올바른 state로 복원을 해야하는데 어떤 상태가 올바른 것인지 알기 어렵고 그저 consitent 한지 여부만 체크할 수 있는 경우가 대부분. 따라서 fsck는 그저 reformat하는 것이 consistency를 유지하기 위한 방법.
해결방안2: Journaling (Write ahead logging)
- 실제 업데이트 이전에 업데이트할 계획을 미리 write하고 업데이트를 수행한다.
- 잘못된 경우엔 log를 보고 faulty operation을 그대로 재수행하여 복구를 할 수 있음. (이전에 쓰인 일부분도 overwrite됨)
- 만약 log가 제대로 안 써졌다면 해당 log를 무시하면 된다. (log가 안 써졌으면 실제 data 역시 안 쓰여진 것이 확실함)
- 쓰여진 log가 있다면 그 log 내용의 업데이트는 반드시 수행되어야 한다.
- EXT2엔 journaling이 없고 EXT3엔 존재함. 따라서 EXT3에는 superblock 옆에 journal block이 존재한다.

Journaling에는 (1) Data Journaling, 그리고 (2) Meta-data Journaling 두 가지 방법이 존재한다.
2.1. Data Journaling
(1) Journal Write
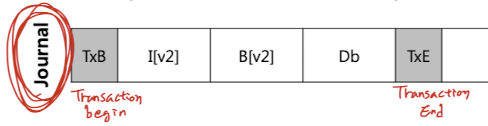
- Inode, bitmap, data에 쓰기 전에 log(journal)에 미리 업데이트 내용을 쓴다.
TxB(Transaction Begin) -> [ inode -> bitmap -> data block ] -> TxE(End)- TxB와 TxE는 TID (Transaction Identifier: transaction 순서를 파악하기 위한 sequential #)를 포함한다.
- Journal(log)을 쓸 때는 한 덩어리씩 연속적으로 write 하기 때문에 시간이 별로 걸리지 않는다.
(2) Checkpoint
- Journal이 아닌 실제 데이터를 업데이트하는 것
- 만약 journal write transaction이 디스크에 제대로 쓰였다면 이제 final loaction에 대해서 실제 update를 할 수 있음
Journal Write 중 Crash가 발생한다면?
- 만약 TxB => [ inode => bitmap => data block ] => TxE 5개의 transaction 각각을 따로 write 한다면 시간이 너무 많이 걸리고, 5개를 한번에 write 하면 디스크가 자체적으로 re-ordering을 해서 문제가 생길 수 있음 (Data block만 안 쓰이고 나머지는 쓰여서 쓰레기 값을 쓰게 되는 경우)
- 따라서 TxE를 제외한 4개를 먼저 쓰고 그 다음에 TxE를 write 해야 안전함.
- journal write (TxB ~ data block) => journal commit (write TxE) => checkpoint
Recovery
일단 superblock을 읽고 journal(log)의 위치를 찾아간다.
- 만약 TxB만 있다면 journal도 안 쓰인 경우이므로 그냥 무시한다.
- 만약 TxB와 TxE는 있는데 checkpoint가 없다면 journal은 온전하지만 실제 write가 실패한 것이므로 journal을 replay하면 쓰려던 내용을 쓸 수 있다.
- 만약 TxB, TxE, checkpoint 모두 있다면 모든 것이 성공적이므로 넘어간다.
Global Transaction
- 두 개의 파일이 같은 디렉토리, inode를 공유한다면 쓸데없는 중복 write가 발생할 수 있다.
- 따라서 디스크 트래픽을 줄이기 위해서 global transaction은 synchronous하게 5초 주기로 한번에 모아서 쓰도록 한다.
Journal(log)의 공간이 꽉 찬다면?
Checkpoint까지 완료된 transaction에 대한 journal은 더 이상 보관할 필요가 없기 때문에 버려도 무방하다.
- Circular 자료구조로 log를 만들어서 오래된 것은 버리고 그 공간을 새로운 데이터가 재사용할 수 있도록 한다.
- 이를 위해서는 checkpoint(실제 write) 이후에 FS가 특정 공간을 free 해주는 작업이 필요하다.
- free할 대상을 정하기 위해서 super block에 가장 오래된, 그리고 가장 최신의 transaction을 마킹한다.
- journal write => journal commit => checkpoint => free
2.2. Metadata Journaling
Insight
: Data block만 쓰고 inode와 bitmap은 업데이트 되지 않은 상태에서 crash가 발생하면 data block은 그냥 없던 값이 되어버리기 때문에 문제가 되지 않는다. 따라서 일단 data block을 먼저 쓰고, 그 뒤에 inode, bitmap에 대해서만 journaling을 해도 아무런 문제가 없다.
- Journaling은 데이터를 두 번 쓰는 것이기 때문에 full-journaling (data-journaling)을 하면 오버헤드가 상당히 크다.
- 따라서 사이즈가 큰 data block은 journaling 하지 않고 inode, bitmap만 journaling하면 오버헤드를 줄일 수 있다. (ordered-journaling = meta-data journaling)
- 이 때 중요한 것은 data block을 먼저 쓰고 journaling을 하는 것!
- data block을 쓴 직후에 crash가 나면 직전에 쓴 data block은 없던 것 취급을 할 수 있는데, 만약 inode와 bitmap journal을 먼저 쓰고 data block을 쓰기 전에 crash가 나면 쓰레기 값을 제대로 쓰인 값으로 인식하게 됨
최종: data write => journal write (TxB, inode, bitmap) => journal commit (TxE) => checkpoint => free
Block Reuse
- 몇몇 meta-data(Revoked Data)는 replay되어선 안 된다.
- 예시
- 디렉토리
foo/가 지워졌고 이에 따라foo/가 있던 1000번 블록이 free 되었다. - 1000번 블록을 재사용해서
foobar가 쓰인다. (순서에 따라 data block)이 먼저 쓰인다. - journal write를 하기 직전에 crash가 났고 FS는 스캐닝을 하며 replay를 수행하는데 journal에는 이미 지워진
foo가 write 될 때 쓰인 내용이 남아있어서 해당 내용을 replay하게 되고foo가 data block에 overwrite 된다.
- 디렉토리
- ext3에서는 revoke record를 남기고 해당 데이터는 replay 않도록 한다
Copy-on-Write
몇몇 fs는 journal을 사용하지 않고 copy-on-write 방식을 사용한다. 즉, 새로운 공간에 copy본을 만들고 그곳에 먼저 새로운 데이터를 업데이트 하고 나서 pointer를 새로운 공간으로 바꾸어주는 방식이다. (overwrite를 통한 업데이트가 아닌 포인터 변경을 통한 업데이트)
'Operating System' 카테고리의 다른 글
| [Operating System] Distributed System and NFS (Network File System) (0) | 2020.06.03 |
|---|---|
| [Operating System] LFS (Log-Structured File System) (0) | 2020.06.03 |
| [Operating System] FFS (Fast File System) (0) | 2020.06.03 |
| [Operating System] File System Implementation (0) | 2020.06.02 |
| [Operating System] File System API (0) | 2020.06.02 |