
2020. 6. 3. 03:23ㆍOperating System
파일 시스템의 종류
1. Local
2. Network
- NFS (Network File System)
- AFS (Andrew File System)
분산 시스템이란?
분산 시스템이란 2개 이상의 기계가 하나의 문제를 풀기 위해서 함께 일하는 것을 의미한다. 분산 시스템은 다음과 같은 이점을 가진다.
- More computing power
- More storage capacity
- Fault tolerance
- Data sharing
분산 시스템에서의 새로운 문제
분산 시스템을 사용함에 따라서 다음과 같은 새로운 고민거리들이 생긴다.
- System failure: 여러 머신 중에 일부만 고장난 경우에 어떻게 복구할 것인가?
- Communication failure: 통신 중에 packet loss 같은 문제가 발생한다면?
단일 시스템이라면 문제가 생기더라도 시스템의 상태를 쉽게 파악 가능하지만 network 상태의 경우 자신이 아닌 다른 기계의 상태는 black box여서 그에 대한 정확한 상태 파악은 불가능하고, 그저 interface에 따라서 통신 행위를 할 수밖에 없다. 다른 기계에서 자신의 state를 알려준다면 상태 파악이 가능할 수도 있지만 그 알려진 상태 마저도 stale state일 수 있다.
Communication
분산 파일 시스템 환경에서 커뮤니케이션을 통해 서로 메세지를 주고 받는 방법에 대해서 살펴보자.
1. Raw Message: UDP (User Datagram Protocol)
- 메세지가 제대로 도착했음을 확인할 수 있는 방법이 없다.
- socket fd에 대해서 read, write를 수행한다.
- 최소한의 reliability만을 제공한다.
- 메세지가 사라질 수도 있고, reorder 될 수도 있고, 복제될 수도 있음.
장점
- 가볍다.
- Application 레벨에서 직접 커뮤니케이션이 제대로 되었는지 확인할 수 있다.
단점
- Reliability를 보장하기 위해서 추가 작업을 따로 해줘야한다.
2. Reliable Message: TCP (Transmission Control Protocol)
ACK
- 메세지 하나 보내고 ACK 받고, 다시 또 하나를 보내고 ACK 받고 하는 식이면 bandwidth가 너무 안 좋아지기 때문에, 한번에 (번호를 붙여서) 여럿을 보내고 (번호가 붙은) ACK를 받는 식으로 통신을 한다.
- 만약에 ACK가 오지 않는다면 어떤 이유 때문인지 파악하기가 어렵다.
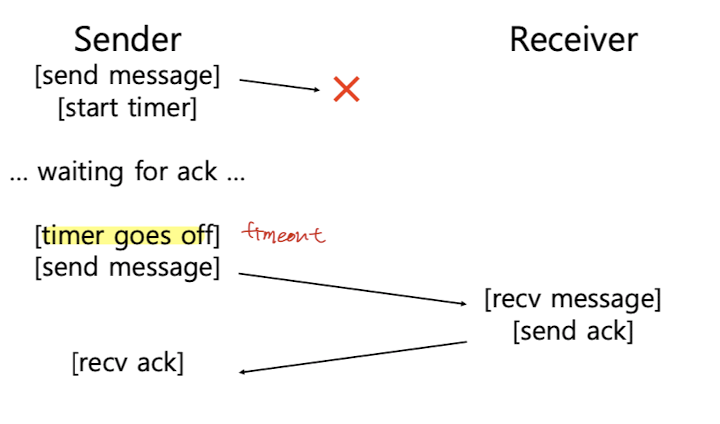
- 특정 시간동안 기다리다가 timeout 하고 재전송 함.
Timeout
- sender가 메세지를 보내고 ACK를 기다리는데 일정 시간 동안 오지 않으면 timeout하고 재전송 한다.
TCP 방식의 문제
[문제1] Timeout 시간이 너무 길면 시스템이 느려지고, 너무 짧으면 안 해도 되는 재전송을 많이 하게 되어서 서버의 부하를 늘리게 됨.
=> [해결] Exponential backoff 식으로 timeout 시간을 정한다.
[문제2] ACK가 오지 않았을 때 원인이 뭔지 확정할 수가 없다.
- Two Generals' Problem: 메세지가 가는 도중에 drop된 건지, 메세지를 받고 ACK를 돌려보냈는데 ACK가 drop된 것인지 알수가 없음.
=> [해결] 이전에 받은 메세지를 기억하고, 새로 들어온 메세지가 이전과 중복된 경우엔 무시한다.
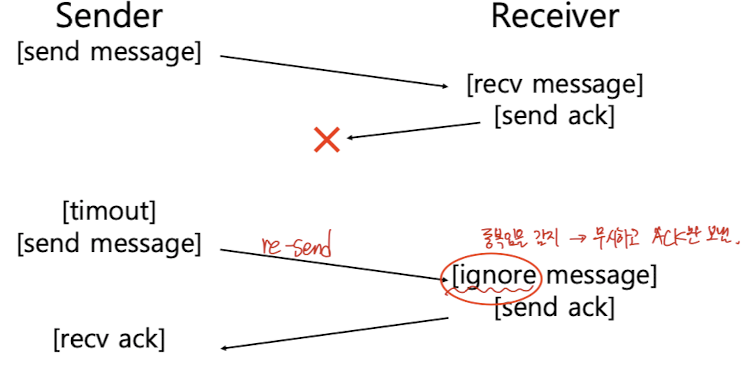
- 단, 모든 메세지에 대해서 유니크한 time stamp가 붙어야 가능한 방법.
- 이전에 받은 메세지를 모두 보관을 하기엔 공간 제약이 있으므로 특정 시간 동안만 기억을 함. (Time stamp가 가장 오래된 것을 버린다.)
3. RPC (Remote Procedure Call)
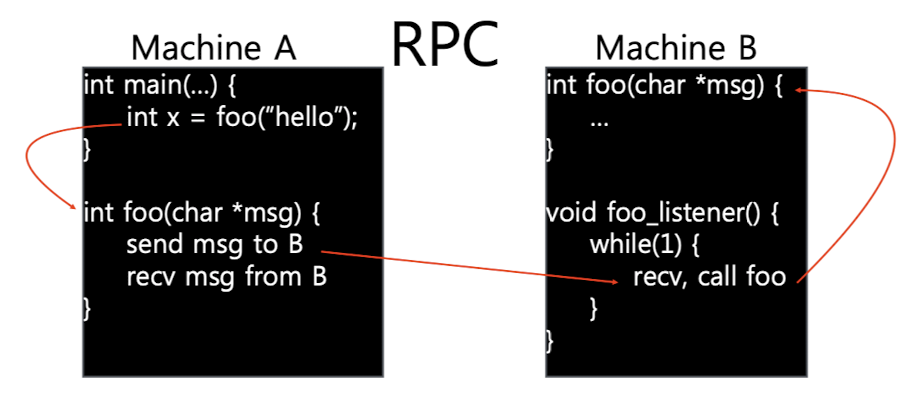
- 마치 local에서 function call을 하듯이, remote 머신에 procedure call을 하고 그 결과를 자신에게 보내도록 한다.
- Client wrapper와 server wrapper가 존재
- Client machine에서 server machine으로 요청을 보내면 $\to$ server는 listen fd를 통해서 요청을 받고 $\to$ 해당 요청에 해당하는 서비스 루틴(함수)을 실행하여 $\to$ 그 결과를 client에게 전달한다.
Stub Generation
- Client - server 간의 커뮤니케이션을 간편하게 하기 위해서 server stub(wrapper)과 client stub을 자동으로 생성하도록 한다.
rpcgen을 많이 사용
// client machine
int main(...) {
int x = foo("hello");
}
// client wrapper(stub)
int foo(char *msg) {
send msg to SERVER
recv msg from SERVER
}
// server machine
int foo(char *msg) {
// do service routine
}
// server wrapper(stub)
void foo_listener() {
while(1) {
recv, call foo
}
}- wrapper generation 시에 여러 가지 자동 conversion(serializing)을 해줌
- client의 function call을 server에게 전달 가능하도록 메세지화
- client의 메세지를 server 함수의 인자로 변환
- server의 리턴 값을 client에게 전달 가능한 메세지화
- server의 메세지를 client function의 리턴 값으로 변환
- 공통된 endianness를 사용하도록 자동 변환
RPC에서는 TCP가 아닌 UDP를 사용한다.
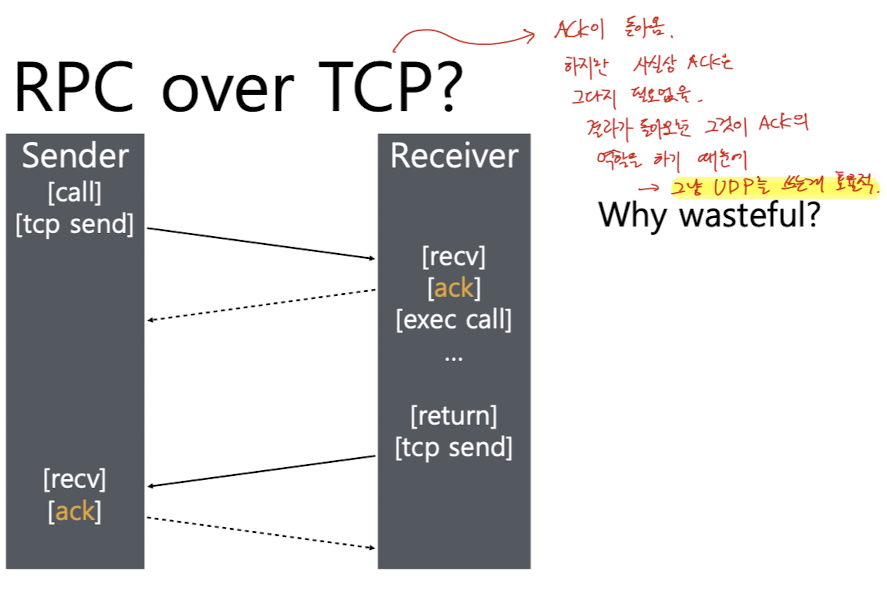
RPC에서는 TCP가 아닌 UDP 프로토콜을 사용한다.
- server의 function call 리턴 값을 메세지로 돌려주는 것 자체가 ACK를 보내는 역할(implicit ACK)을 하는 것과 동일하기 때문에 가벼운 UDP를 사용하는 것이 낫다.
-
함수의 연산에 시간이 오래 걸리는 경우에만 따로 ACK를 보내준다.
분산 파일 시스템 (NFS만 다룸)
- Local FS: 동일한 머신에서 돌아가는 프로세스들이 서로 파일을 공유한다.
- Network FS: 서로 다른 머신에서 돌아가는 프로세스들이 파일을 공유한다.
분산 파일 시스템의 조건
- 빠르고 쉽게 crash recovery가 가능해야함
- 마치 local에서 접근하듯이 trasnparent access가 가능해야함
- local과 완전 동일한 접근 속도는 아니더라도 reasonable한 속도여야함
NFS
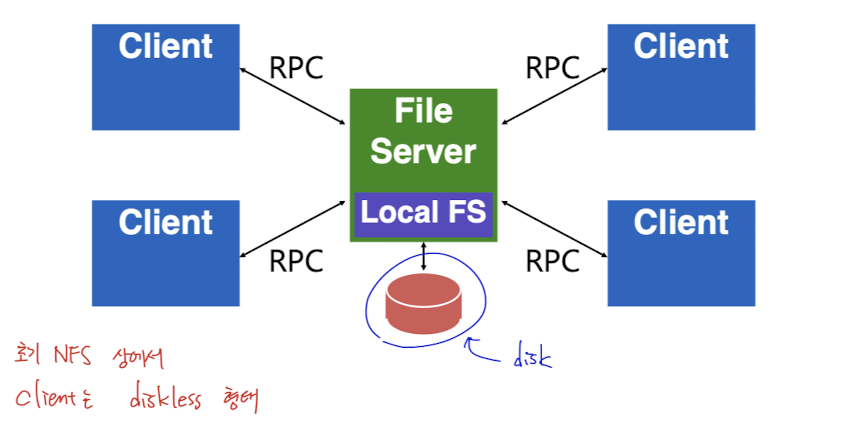
- 하나의 파일 서버가 존재하고 여러 client들은 이 서버와 RPC로 통신한다.
- 클라이언트에서는 자신의 local FS 이외에 NFS를 마운트 하면, 마치 local 파일을 read 하듯이 NFS의 파일을 읽을 수 있다.
- 클라이언트가 NFS 파일을 read 하려고 하면, server는 자신의 local FS에서 읽은 값을 클라이언트에게 보내주고 클라언트는 그 값을 읽게 된다.
NFS: Server의 file을 어떻게 read할 것인가?
1. File Descriptor를 이용한 RPC syscall
- 클라이언트는 RPC를 통해서 서버에 대해서
read(fd)시스템콜을 호출한다. - Wrapper를 통해 메세지를 전달받은 서버는 함수를 실행하고 그 결과를 wrapper를 통해 클라이언트에게 전달한다.
- 이 때 어떤 파일을 읽을 것인지는
fd를 통해 전달된다.
[문제] crash가 났을 때 복구가 어렵다.
- 서버에서 클라이언트 요청에 따라 fd에 해당하는 파일을 read 하는 도중에 crash가 난다면 reboot를 해서 다시 읽어야하는데 reboot를 하면 fd가 바뀌게 되어서 동일한 fd로 read가 불가능하다.
- 따라서 crash 이전에 미리 fd를 따로 저장해두어야만 한다. (좋은 방법 X)
- 느리고, client 측의 crash에 대해서는 대처하기 어렵고, fd를 GC 해줘야하는 오버헤드가 있음.
2. (Stateless Protocol) Request에 모든 read 정보를 담아서 보낸다.
- 서버는 클라이언트의 요청에 대한 정보를 보관하지 않는다.
- Crash가 나고 reboot를 했을 때 다시 복원을 해야할 state가 존재하지 않는다. (fault tolerance 증가)
- API의 변화:
read(fd)$\to$pread(path, buf, size, offset)
[문제] 매 R/W 요청 마다 path lookup을 해야한다.
=> [해결] server 측에서 caching을 하면 disk lookup을 줄일 수 있다.
3. Inode Request
- Traversal 오버헤드가 큰 Path 대신 inode를 통해 요청을 보낸다.
pread(path, buf, size, offset)$\to$pread(inode, buf, size, offset)- 참고) path를 통해 inode를 얻는 방법:
inode = open(path)
[문제] 서버에서 파일이 지워진 경우에도 클라이언트의 요청에 의해 stale inode가 재사용 되어서 이상한 값을 읽을 수 있다.
4. [최종 결론] file handles
- File handle = <volumeID, inode number, generation number>
- volumeID: NFS가 여러 개일 경우 구분하기 위함
- inode #: inode를 통해 서버의 파일 접근
- generation #: generation을 통해서 inode가 이전 것인지 최신 것인지 알 수 있음
- fh 획득:
fh = open(path) pread(fh, buf, size, offset)
[문제] append와 같은 non-idempotent operation 수행 불가.
Idempotent Operation이란?
f()가 idempotent하다면, f(); f(); f(); ...와 같이 몇번을 실행해도 그 결과가 동일하다.
Ex)
- idempotent op 예시: write, read
- non-idempotent op 예시: append, mkdir, create
NFS에서는 append를 비롯한 non-idempotent operation들이 불가능하다. 왜냐하면 NFS는 그 어떤 state도 기억하지 않기 때문이다. 즉, client가 이전에 보낸 요청과 관련해서는 그 어떤 상태도 기억한다고 보장할 수가 없다.
- NFS는 stateless이기 때문에 append 명령 2개가 중복되어 오거나 순서가 re-ordering 되었을 때 제대로 처리하지 못 할 수 있다. 따라서 append를 하지 않고 특정 시점(offset)부터 write를 하라는 식으로 명령을 변경하여 RPC한다.
- append는 특정 offset부터 write하는 명령으로 바꿔야하고, mkdir, create는 '절대 경로'를 통해서 파일, 디렉토리 생성을 해야한다.
NFS: Cache Consistency
NFS의 disk file은 세곳에 캐싱된다.
- Server memory
- Client disk
- Client memory
"원래 disk, 그리고 캐싱된 모든 곳들의 버전들의 sync를 어떻게 맞출까?"
아래 그림을 살펴보자. 만약 client 1, 2가 둘다 서버의 file A를 가지고 있는 상태에서 client 1이 A에 write를 한다면, 오직 client 1만 새로운 버전(B)을 갖고 있는 상태가 된다.
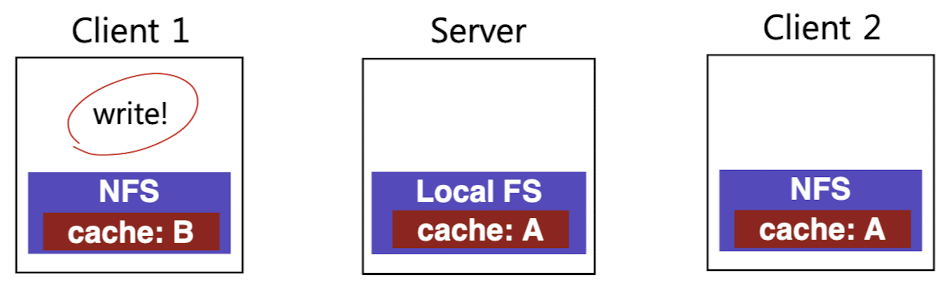
이와 같은 상황에서는 invalidation 메커니즘이 필요하다.
- Client 1이 write 시엔 그 파일을 server로 flush(write-through)하고, Client 2가 read 시엔 server로부터 새 버전의 파일을 받아 캐시 업데이트를 해줘야 한다.
- Client 2 입장에서는 Client 1이 file B를 업데이트 했다는 것을 알지 못하기 때문에 이 사실을 알기 위해선 read 이전에 자신이 캐싱한 copy가 최신 버전인지, 더 최신 버전이 존재하는지 확인 해야한다. (by time stamp)
- Data block을 사용하기 전에 stat() 함수를 서버에게 호출(RPC)
- Cache의 time stamp를 비교해서 자신의 버전이 이전 것이라면 re-fetch.
[문제1] client가 매번 데이터를 읽을 때마다 서버에게 stat 요청이 감 $\to$ 지나친 트래픽 발생 (90% 이상의 요청이 stat)
=> [해결1] stat의 결과도 캐싱하여 3초에 한번 정도만 서버에게 새로 stat 요청을 하도록 한다.
[문제2] 하나의 client에서 write가 이루어질 때마다 server에 write-through를 하면 트래픽이 너무 커진다.
=> [해결2] 따라서 fd가 close() 했을 때만 write-through를 한다.
'Operating System' 카테고리의 다른 글
| [Operating System] Condition Variable (0) | 2020.06.03 |
|---|---|
| [Operating System] Locks (0) | 2020.06.03 |
| [Operating System] LFS (Log-Structured File System) (0) | 2020.06.03 |
| [Operating System] Crash Consistency (0) | 2020.06.03 |
| [Operating System] FFS (Fast File System) (0) | 2020.06.03 |