
2020. 7. 5. 16:57ㆍResearch
Paper Link: https://arxiv.org/pdf/1608.00367.pdf
Image super-resolution(SR) 태스크에서 SRCNN이 좋은 성능을 거두었지만 real-time 서빙을 하기에는 연산 비용이 너무 크다는 문제가 있다. 이 논문에서는 모래시계 모양의(encoder-decoder 구조를 생각하면 된다.) CNN 구조를 활용하여 기존의 SRCNN을 경량화, 가속화하는 것에 중점을 두었다. 이를 위해서 다음과 같은 3가지 방법을 취하였다.
- DCGAN, pix2pix 등에서 사용하는 transposed convolution(deconv)을 네트워크의 후반부에 활용하여, 저해상도(LR)의 입력 이미지와 고해상도(HR)의 출력 이미지 간의 매핑이 E2E로 학습가능한 네트워크 구조를 만든다.
- 앞서 모래시계 모양의 CNN 구조라고 언급했던 것처럼 transposed convolution을 통해 feature map을 확장시키기 이전에 input feature map의 차원을 축소시켜 latent feature를 추출할 수 있도록 한다.
- 더 작은 필터 크기를 사용하여 연산량을 줄였고, 그 대신에 더 많은 레이어를 사용한다.
이 논문에서는 deconvolution이라는 용어를 사용하는데 이는 잘못된 용어이다.
Some sources use the name deconvolution, which is inappropriate because it’s not a deconvolution. To make things worse deconvolutions do exists, but they’re not common in the field of deep learning. An actual deconvolution reverts the process of a convolution. Imagine inputting an image into a single convolutional layer. Now take the output, throw it into a black box and out comes your original image again. This black box does a deconvolution. It is the mathematical inverse of what a convolutional layer does.
(출처: An Introduction to different Types of Convolutions in Deep Learning)
따라서 이 포스팅에서는 deconvolution 대신에 transposed convolution이라는 용어를 사용하도록 하겠다.
Introduction
Single image super-resolution(SR)은 저해상도(LR)의 이미지를 고해상도(HR)의 이미지로 복원하는 태스크를 의미한다. SRCNN은 SR 태스크에 최초로 딥러닝을 활용한 모델인데, 상당히 뛰어난 성과를 거두었고 이에 기반하여 이후에 Fast R-CNN, Faster R-CNN 등이 등장하였다. SRCNN은 SR 문제를 해결하는 데에 좋은 성능을 보이긴 하지만 real-time 서빙을 하기에는 너무 느리다는 문제가 있다. 예를 들어 240x240 이미지를 3배 크기로 upsample 하는 경우 SRCNN은 1.32 fps의 throughput을 보이지만 real-time 성능을 내기위해서는 약 17배에 해당하는 24 fps에 도달해야 한다.
SRCNN의 속도 한계에는 2가지 이유가 있다.
- 전처리 단계에서 입력 LR 이미지는 삼차보간법(bicubic interpolation)을 통해서 원하는 이미지 사이즈(HR 이미지 사이즈와 동일한 크기)로 upsampling 되는데 이렇게 upsampling 된 이미지에 대해서 convolution을 수행하면 계산 비용이 크게 증가한다. 만약 n배의 크기로 upsampling 하는 경우, upsampling 하지 않은 original LR 이미지 대비 $n^2$배 만큼 연산량이 증가한다.
- SRCNN은 patch extraction => non-linear mapping => reconstruction의 과정을 거치는데, 다차원 LR feature space에서 또 다른 다차원 HR feature sapce로 매핑하는 non-linear mapping 단계에서 mapping 레이어(= convolution 레이어)의 너비를 늘릴 수록 좋은 accuracy를 얻을 수 있지만 연산 비용이 증가하는 문제가 있다.
위의 두 가지 문제에 대해서 이 논문에서는 각각 다음과 같은 해결책을 제시한다.
- Bicubic interpolation 대신 네트워크 후반부에 transposed convolution을 사용한다. 이 경우엔 original LR 이미지에 대해서 convolution을 수행하기 때문에 bicubic interpolation을 통해 upsampling 된 전처리 이미지에 대해 convolution을 하는 것보다 $n^2$배 만큼 연산량을 줄일 수 있다.
- Autoencoder나 pix2pix에서 그러하듯이 대칭적인 encoder-decoder 구조를 사용한다.(논문에서는 모래시계 구조라고 설명한다.) Encoder에서는 저차원 feature space로의 매핑을 통해 중요한 feature들을 추출해내고 decoder에서 이를 확장한다.
위 두 가지 기법들이 적용된 모델이 바로 이 논문에서 소개하는 Fast Super-Resolution Convolutional Neural Network(FSRCNN)이다. FSRCNN은 기존의 SRCNN-Ex(SRCNN보다 6배 많은 파라미터를 가진 larger version) 보다도 높은 성능을 보이면서도 40배나 빠른 속도를 낸다. 마찬가지로 FSRCNN의 small version인 FSRCNN-s는 SRCNN과 비교했을 때 거의 동일한 성능을 내면서도 17.36배나 빠른 속도를 낸다. 이는 CPU에서 24 fps의 처리량을 낼 수 있는 속도이기 때문에 real-time 서빙이 가능한 속도라고 할 수 있다.

FSRCNN이 갖는 또 한 가지 중요한 장점은 encoder 부분에 있는 모든 convolution 레이어가 decoder의 upscaling factor가 달라져도 동일하게 재사용될 수 있기 때문에 다양한 upsampling factor에 대해서 학습, 테스트가 용이하다는 것이다. 따라서 학습 과정에서 encoder의 convolution 레이어는 pretraining된 것을 그대로 사용하고, decoder의 transposed convolution만 upsampling factor에 맞게 fine-tuning하면 된다. 마찬가지로, 테스트 과정에서 역시 encoder의 convolution은 한 번만 수행하고 decoder의 transposed convolution만 각 upsampling factor에 맞게 따로 수행하면 된다.
Fast Super-Resolution by CNN
1. SRCNN
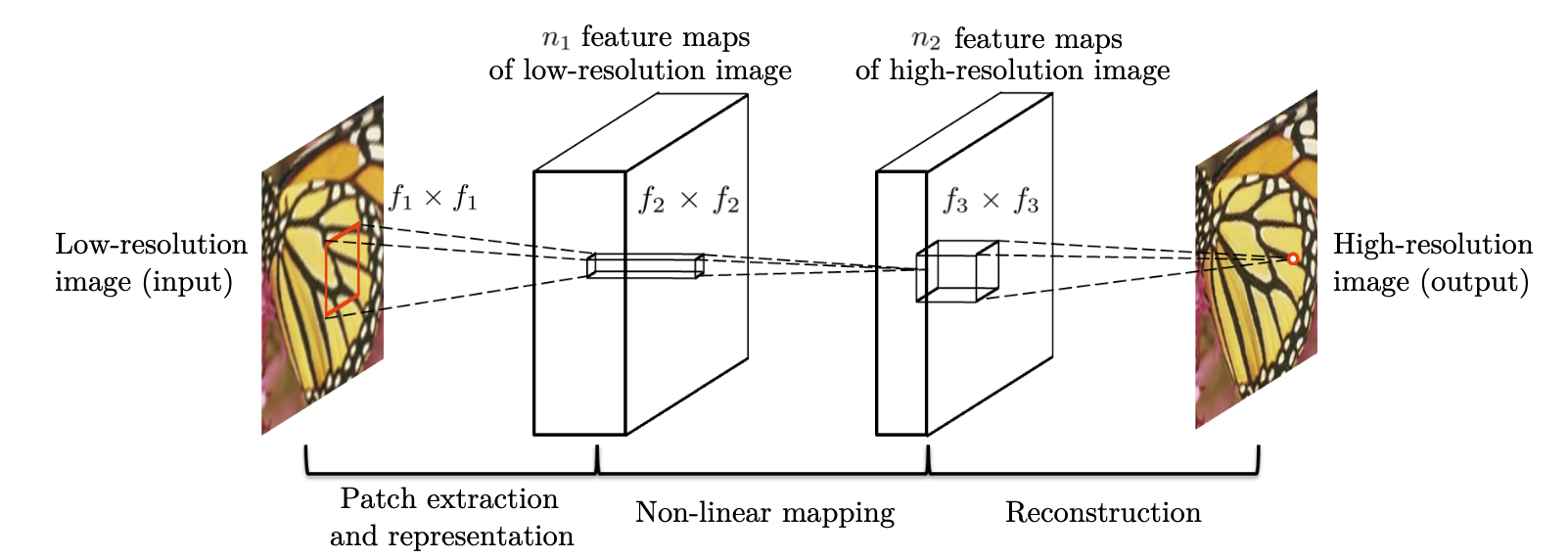
FSRCNN을 살펴보기 전에 SRCNN에 대해서 먼저 간단히 살펴볼 필요가 있다. SRCNN에서는 bicubic interpolation을 통해서 전처리 된 LR 이미지 $Y$와 HR 이미지 $X$ 간의 E2E mapping function인 $F$를 학습하는 것이 목적이다. 위의 그림에서 볼 수 있듯, 총 3 단계를 거쳐서 HR 이미지를 얻어내는데, 각각의 부분의 역할은 다음과 같다. ($W_i$는 convolution의 filter 파라미터, $B_i$는 bias, $*$는 convolution 연산을 의미한다.
(1) Patch extraction and representation (Conv + ReLU)

- Bicubic interpolation을 통해 전처리된 입력 이미지 $Y$에 대해서 patch들을 추출해내고, 각 patch가 다차원 feature vector로 표현되도록 한다.
(2) Non-linear mapping (Conv + ReLU)
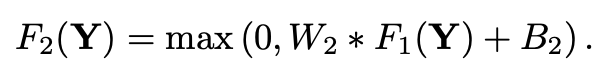
- 비선형 매핑 함수를 통해서 LR feature vector를 또 다른 다차원 feature vector(HR feature vector)로 매핑한다.
(3) Reconstruction (Conv)

- HR feature vector로부터 최종 출력 HR 이미지를 얻는다.
2. FSRCNN

FSRCNN은 총 5단계의 네트워크 구조를 갖는다. 앞의 네 단계는 convolution 레이어들로 구성되어 있고, 마지막 단계는 transposed convolution 레이어로 구성된다. 편의를 위해 다음과 같이 notation을 정의하기로 하자.
- $f_i$: $i$번째 레이어의 필터 크기
- $n_i$: $i$번째 레이어의 필터 개수 (= 출력 채널 수)
- $c_i$: $i$번째 레이어의 입력 채널 수
- $Conv(f_i, n_i, c_i)$: convolution
- $DeConv(f_i, n_i, c_i)$: transposed convolution
(1) Feature extraction: $Conv(5, d, 1)$
이 부분은 SRCNN에서 첫 번째 단계와 동일한 연산을 수행하지만 입력으로 들어오는 이미지가 bicubic interpolation 전처리를 거친 이미지($Y$)가 아니라 original LR 이미지($Y_s$)라는 점에서 차이가 있다. SRCNN에서는 첫 번째 레이어에서 9x9 필터를 사용하는데, 이는 interpolation을 통해 upscaling 된 이미지인 $Y$에 대해 적용되는 것이다. 따라서 interpolation 없이 original LR 이미지 $Y_s$를 사용하는 FSRCNN에서는 5x5 필터를 사용한다. $Y$의 대부분 픽셀들은 $Y_s$에서 interpolate 된 것이므로 이렇게 하더라도 정보의 소실은 거의 없다고 볼 수 있다.
첫 번째 레이어의 입력 채널 수 $c_1$은 SRCNN과 같이 1로 설정하였고, 출력 채널 수 $n_1$는 $d$로 설정하였다.
(2) Shrinking: $Conv(1, s, d)$
SRCNN에서는 non-linear mapping 단계에서 LR feature space에서 HR feature space로의 매핑이 바로 이루어졌지만, LR feature 벡터의 채널 수(= $d$)가 일반적으로 상당히 큰 값이기 때문에 이대로 convolution을 수행하면 연산 비용이 너무 커진다. 따라서 GoogLeNet을 비롯한 여러 모델들이 활용한 1x1 convolution을 통해 채널 수를 줄임으로써 연산 오버헤드를 감소시킨다. 출력 채널 수에 해당하는 $s$는 입력 채널 수 $d$보다 더 작은 수이다. ($n_2 = s << d$)
(3) Non-linear mapping: $Conv(3, s, s) \times m$
Non-linear mapping 단계는 SR 성능에 가장 큰 영향을 주는 핵심 단계이며, 이 때 제일 중요한 요소가 레이어의 너비(필터 개수)와 깊이(레이어 개수)이다. SRCNN에서는 5x5 레이어를 사용했을 때 1x1 레이어를 사용했을 때보다 좋은 성능을 보였지만 이는 레이어의 깊이가 얕을 때에 대해서만 실험한 것이었다.
FSRCNN에서는 1과 5의 중간 크기인 3을 필터 크기로 잡았고, 줄어든 필터 크기로 절약된 연산량만큼 레이어의 깊이를 늘렸다. (총 $m$개의 3x3 convolution 레이어) 이 때 feature map 채널 수의 일관성을 위하여 필터 개수는 입력 채널 수와 같은 $s$로 잡았다.
(4) Expanding: $Conv(1, d, s)$
Shrinking 단계에서 1x1 convolution을 통해서 채널 수를 줄여 연산량을 감소시켰다면, expanding 단계에서는 SR 성능을 위해서 feature map 채널 수를 shrinking 이전으로 복원한다. 이 때도 shrinking에서처럼 연산량이 적은 1x1 convolution을 활용한다.
(5) Transposed Convolution: $DeConv(9, 1, d)$
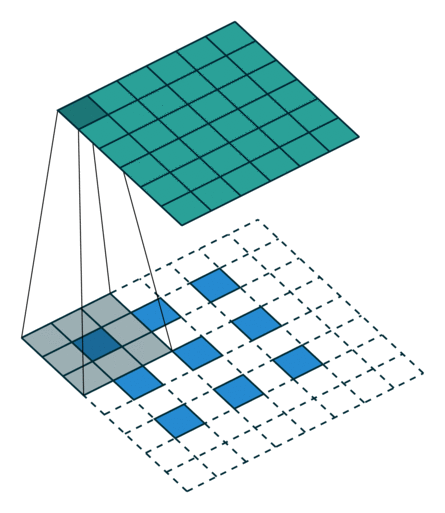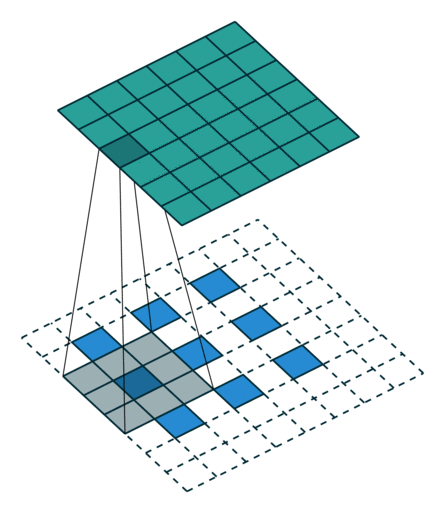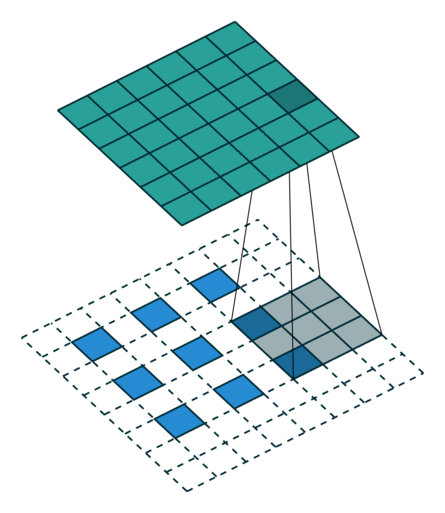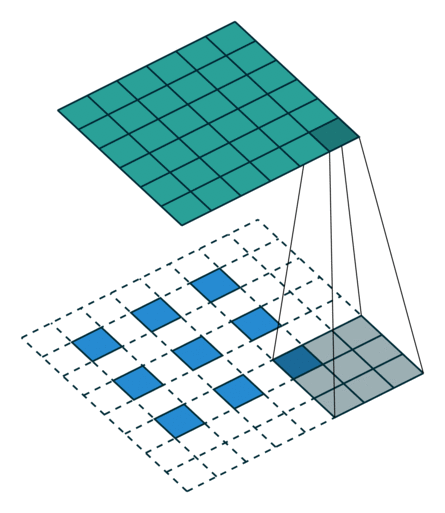
Transposed convolution은 convolution을 통해 추출한 feature map을 다시 확장시키는 upsampling 기능을 한다. 위의 그림은 stride=2, padding=1인 경우에 deconvolution을 수행한 것이다. Transposed convolution에서는 출력 feature map의 크기가 stride 크기의 배수로 증가하기 때문에 stride가 곧 upsampling factor가 된다.
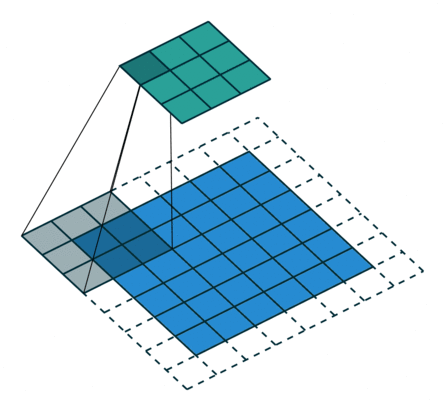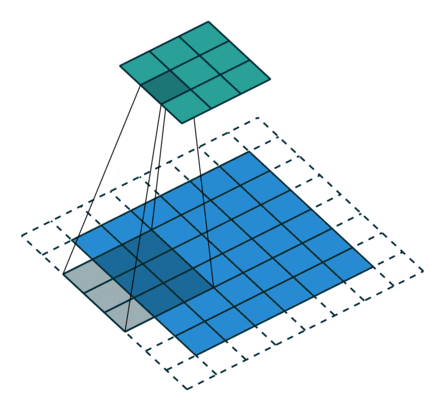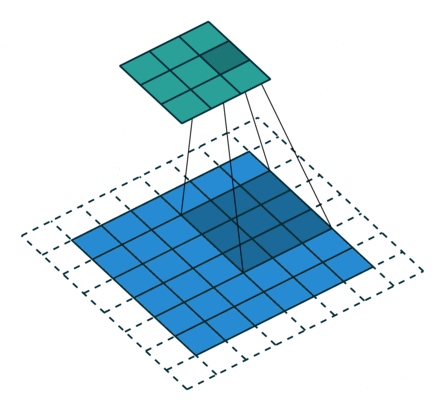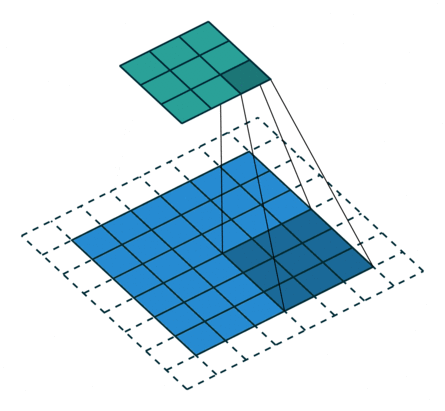
Transposed convolution의 필터 크기는 transposed convolution의 역에 해당하는 convolution의 필터 크기와 동일하게 잡아야 한다. 예를 들어 3x3 feature map에서 6x6 feature map을 만들어내는 transposed convolution(위의 그림)의 반대는 6x6 feature map에서 3x3 feature map을 추출하는 convolution이다. 6x6 feature map에서 3x3 feature map을 추출하기 위해서는 아래의 그림과 같이 padding=1, stride=2, filter size=3을 사용해야 하는데, 이는 위의 그림에서 살펴본 transposed convolution의 세팅과 완전히 동일하다.
SRCNN의 첫 번째 레이어에서 bicubic interpolation을 통해 upsampling 된 LR 이미지(HR 이미지와 동일한 사이즈)에 convolution을 적용할 때 9x9 필터를 사용했으므로, FSRCNN에서도 같은 크기로 upsampling 하려면 동일하게 9x9 필터를 사용하여 transposed convolution을 수행하면 된다.
3. SCRNN과 FSRCNN의 차이점
다시 한번 정리하자면, FSRCNN은 다음과 같은 새로운 방법을 도입하여 SRCNN보다 좋은 성능을 보이면서도 더 빠른 속도를 낼 수 있다.
- FSRCNN에서는 SRCNN과 달리 bicubic interpolation을 통해 전처리된 LR 이미지를 사용하지 않고 original LR 이미지를 그대로 사용하여 convolution에서의 연산량을 줄인다.($n^2$배)
- 네트워크 후반부에서 upscaling을 위해서 transposed convolution이 활용된다.
- SRCNN의 non-linear mapping 단계가 FSRCNN에서는 shrinking, mapping, expanding 세 단계로 분리된다.
- FSRCNN에서는 더 작은 필터 크기를 사용하고, 네트워크의 깊이는 더 깊어졌다.
Reference
[1] https://github.com/vdumoulin/conv_arithmetic
vdumoulin/conv_arithmetic
A technical report on convolution arithmetic in the context of deep learning - vdumoulin/conv_arithmetic
github.com
[2] https://jamiekang.github.io/2017/04/24/image-super-resolution-using-deep-convolutional-networks/
Image Super-Resolution Using Deep Convolutional Networks · Pull Requests to Tomorrow
Image Super-Resolution Using Deep Convolutional Networks 24 Apr 2017 | PR12, Paper, Machine Learning, CNN, SRCNN 이번 논문은 2015년 IEEE Transactions on Pattern Analysis and Machine Intelligence에 발표된 “Image Super-Resolution Using Deep Convo
jamiekang.github.io