
2020. 1. 16. 21:32ㆍResearch
이 논문은 JavaScript를 타켓으로 하고 있지만 요즘 연구하고 있는 pytorch의 JIT(just-in-time) 컴파일러 연구에 중요한 바탕이 되는 연구이기에 리뷰를 작성한다.
Abstract
자바스크립트와 같은 dynamic language(js, python, ruby, ...)는 static language(c, c++, ...)와 비교했을 때 컴파일에 많은 어려움이 존재한다. 그 주된 이유는 변수의 type이나 branch와 같은 정보들을 compile time에는 알 수 없고, runtime이 되어서야 알 수 있기 때문이다. Python과 같은 dynamic language는 컴파일 시점에 구체적인 타입에 대한 정보가 없기 때문에, 기존의 컴파일러들은 가능한 모든 조합의 타입들을 런타임에 핸들링할 수 있도록 (오버헤드를 감수하고) generic code를 생성해야했다.
이 논문에서는 이와 같은 비효율성을 타개하기 위하여 런타임에 빈번하게 실행되는 loop의 정보들을 수집하고, 이를 바탕으로 실행된 프로그램에 맞는 machine code를 생성하는 방식을 취하였다. 그 결과 벤치마크 프로그램에 대한 실험에서 약 10배 가량의 성능 향상을 기록하였다.
1. Introduction
Static vs Dynamic Type
- JS, python, ruby와 같은 언어는 상당히 high level의 표현력을 가지고 있기에 C, C++과 같은 언어와 비교하였을 때 비전공자들이 접근하기 위한 진입장벽이 낮은 편이다.
- JS의 경우 web 개발에서 뗄 수 없는 존재이다.
- C와 같은 static type language의 경우, 타입 정보가 compile time에 명시적으로 존재하기 때문에 컴파일러가 최적화된 머신 코드를 생성하기 용이하다. 반면, JS와 같은 경우 타입 정보는 런타임에 결정 된다.
- 정확한 타입 정보가 없다면 컴파일러는 모든 가능할만한 타입의 경우의 수를 모두 따져서 머신 코드를 생성해야하므로 최적화 측면에서 좋은 성능을 기대하기 어렵다.
Breakthrough: Trace
- Trace 기반의 compile 기법 도입
- Trace란? 프로그램이 실행되면서 시스템은 hot(자주 실행되는) bytecode sequence를 기록하고, 이를 최적화된 머신 코드로 변환한다.
- Temporal, spatial locality 때문에 프로그램은 실행되면 대부분의 시간을 loop에서 소비한다.
- cf) 이 논문에 등장하는 내용은 아니지만 ML에서 학습과정은 동일한 function을 하는 반복적인 step iteration을 통해서 이루어지므로 딥러닝 프레임워크의 최적화에도 이러한 컨셉을 적극 활용 가능하다. 이에 대해서는 추후에 포스팅을 할 예정이다.
- 위와 같은 전제로 인해서 trace 기반의 컴파일러는 실제 프로그램을 실행하면서 그에 적합한 type-specialized trace를 생성할 수 있다.
- Trace는 프로그램 코드의 전체를 커버하는 것이 아니라 trace를 생성하기 위해 실행이 되는 동안 hit된 path에 대해서만 커버를 한다. 즉 여러 개의 branch가 존재한다면 여러가지 분기 경우의 수 중에서 trace 생성이 되는 동안 거쳐간 branch path에 대해서만 커버를 한다.
- Trace는 speculation(branch나 type과 같은 정보에 대한 예측)을 validate할 수 있도록 speculative point마다 guard(check) 라는 것을 두는데, 만약에 trace에서 파악한 branch path나 variable type과는 다른 경우의 수가 발생한다면 해당 부분에 guard hit이 발생한다. 이 경우에 기존 trace는 exit하고, VM은 새로운 path에 대한 정보를 반영하여 새로운 trace tree를 구성한다.
Issue : Nested Loop
- Nested loop의 경우에 최적화된 trace를 뽑기가 어렵다.
- 프로그램에서는 inner loop가 outer loop보다 먼저 빈번하게 실행(hot)되는데 이에 따라 inner loop에 대한 trace가 먼저 생성된다.
- 만약 inner loop에서 invalidation이 발생하여 exit하게 되면, VM은 새로운 branch의 존재를 인식하게 되고 이를 반영한 새로운 branch trace를 생성하기 위해서 다시 inner loop로 들어가려는 시도를 한다. 하지만 이 과정에서 또 다른 exit이 발생하면 그 오버헤드가 커진다.
- 이를 해결하기 위해서 Nested Trace Tree를 활용한다.
- outer loop에 도달하면 inner loop tree를 확장하는 것을 중단
- outer loop header에서 새로운 trace를 생성하기 시작
- 만약 outer loop를 돌다가 inner loop에 도달하면 1.에서 만들던 inner tree를 불러와서 이를 outer trace에 merge한다.
Contribution
이 논문에서 제시하는 selling point(contribution)은 다음과 같다.
- Nested loop를 nested trace tree를 통해 표현하여 프로그램에 대한 trace tree를 동적으로 생성하기 위한 알고리즘 제시
- 어떻게 dynamic language program으로부터 type specialized machine code를 생성할 수 있는가?
- 여러 벤치마크에서 2~20배의 성능 향상을 기록
2. Overview: Example Tracing Run

이 연구에서는 기존의 SpiderMonkey 인터프리터에 trace 기법을 추가하여 TraceMonkey(이하 TM)라는 이름의 새로운 인터프리터를 디자인하였다. 위의 그림에서는 TM의 전체 workflow를 FSM 형태로 도식화하였는데, 각각 box의 색깔을 의미는 다음과 같다.
- 가장 짙은 색의 box는 TM이 JS 코드를 이전에 컴파일된 trace를 통해서 실행하는 state
- 옅은 회색의 box는 TM이 JS 코드를 기존 인터프리터 하에서 실행하는 state
- 흰색 box는 오버헤드 step에 해당하는 state
따라서 코드를 실행할때 가장 짙은 box의 state에 최대한 오래 머무를 수 있어야 오버헤드를 최대한 줄일 수 있다.
구체적인 Work Flow
- Bytecode 인터프리터를 통해서 프로그램을 실행한다.
- Trace monitor에서는 새로운 path를 record할지 기존의 native trace를 따라서 실행할지 결정한다.
- 프로그램 실행 직후에는 아직 컴파일된 trace가 존재하지 않기 때문에 monitor는 각 loop의 back edge가 몇 번이나 거쳐졌는지 세고, 특정 threshold를 넘어서면 해당 path는 hot하다고 결정한다.
1 for(var i=2; i<100; ++i) {
2 if (!primes[i])
3 continue;
4 for(var k=i+i; i<100; k+=i)
5 primes[k] = false;
6 }
// primes[2:99] is initialized to 'true'
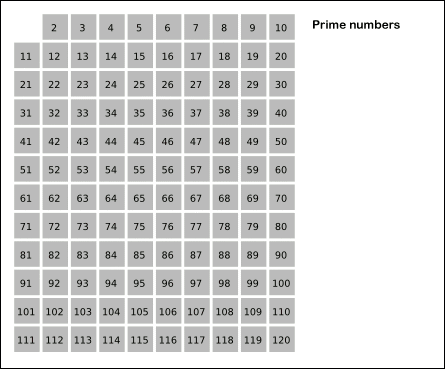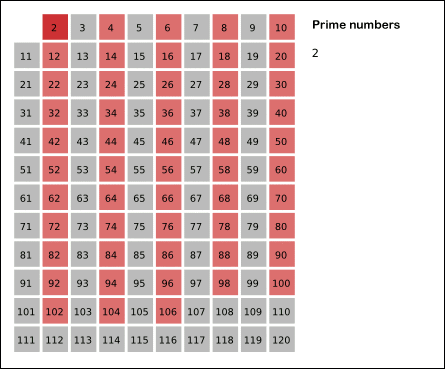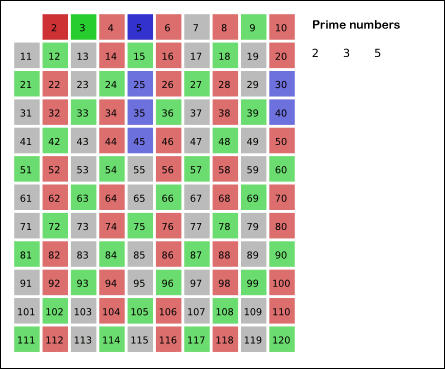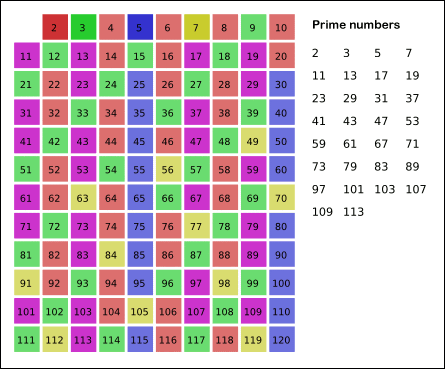
위의 코드는 2부터 99까지의 수 중에서 prime number를 찾아내는 "에라토스테네스의 체(sieve of Eratosthenes)" 알고리즘으로 이 논문에서는 이 프로그램을 예시로 설명을 전개하고 있다. (아래의 그림은 위키피디아 출처) 이 코드를 실행했을 때 일어나는 일을 iteration 별로 살펴보면 다음과 같다.
- i=2
- hot 상태에 있는 line 4-5의 inner loop에 들어가므로, line 4에 도달했을 때 TM은 recording mode에 들어간다.
- recording mode에서는 실행되는 코드의 LIR(Low-level Intermediate Representation)과 guard(branch와 type의 분기점)를 기록한다. (operation과 operand의 타입 등이 기록)
- 만약 모든 guard를 패스한다면 trace가 완성된 것이다.
- 실행 중에 loop header를 만나거나 exit할 경우 recording은 종료된다. 따라서 첫 번째 iter를 돌고 다시 line 4에 도달했을 때 recording은 꺼진다.
- recording 종료 후엔 만들어진 trace의 타입 정보를 통해 최적화된 native code를 생성한다. (T45)
- i=3
- line 1의 loop header는 hot 상태가 되고, 이에 따라 recording이 시작된다.
- recording이 line 4에 도달했을 때 이미 trace가 존재하는 inner loop header를 만나게 되고, 현재 outer loop trace에 inner loop trace를 merge 한다.
- inner loop trace subroutine을 호출하고, 서브루틴이 끝나면 다시 recorder로 리턴한다.
- 만약 inner loop trace가 side exit 없이 수행되었다면 outer trace의 일부로 합친다.
- inner loop trace subroutine을 호출하고, 서브루틴이 끝나면 다시 recorder로 리턴한다.
- outer loop를 모두 돌아 다시 line 1에 도달하면 recording을 종료하고, 만들어진 trace를 컴파일한다. (T16)
- i=4
- T16을 호출한다.
- 4는 소수가 아니기 때문에 T16에서는 tracking하고 있지 않은 line 2의 if 문이 taken 되고, 이에 따라 side exit이 발생한다.
- 비록 side exit이 발생했으나 아직 딱 한번 발생하여 hot 상태는 아니기 때문에, recording을 하진 않는다. TM은 인터프리터를 통해서
continue;를 실행한다.
- i=5
- line 1에서 T16을 호출하고, line 4에서는 (T16의 일부인) T45가 호출된다.
- trace에 완벽하게 부합한 실행이 이루어진다.
- i=6
- T16을 호출한다.
- 6은 소수가 아니기 때문에 if 문이 taken 됨에 따라 side exit이 한번 더 발생하여 hot 상태가 된다.
- recording이 시작되고 새로운 trace인 T231이 만들어지고 기존의 trace에 merge 된다.
continue;가 실행되면 outer loop header인 line 1에 도달
- TM은 전체 loop를 충분히 커버할 수 있는 trace를 compile 하였기 때문에 나머지 프로그램을 완벽하게 native code에서 실행될 수 있다.
위의 코드를 컴파일하여 생성된 LIR(Low-level Intermediate Representation)은 다음과 같다.

그리고 이를 컴파일하여 생성한 x86 어셈블리 코드는 다음과 같다. (*) 로 표시된 부분은 side exit이 taken되는 부분이 없다는 것을 알고있는 ideally optimized compiler에서 생략될 수 있는 부분을 나타낸다.
