
2020. 2. 1. 16:32ㆍResearch
현존하는 DNN 프레임워크는 개발자가 매뉴얼하게 짜놓은 규칙에 따라서 graph optimzation을 수행하는데 이는 scalable 하지 못하며 모든 optimizable option들을 반영하지 못하는 단점이 있다. TASO는 자동으로 효율적인 graph substitution을 생성하는 최초의 DNN graph optimizer이다.
TASO Github: https://github.com/jiazhihao/TASO
substitutions
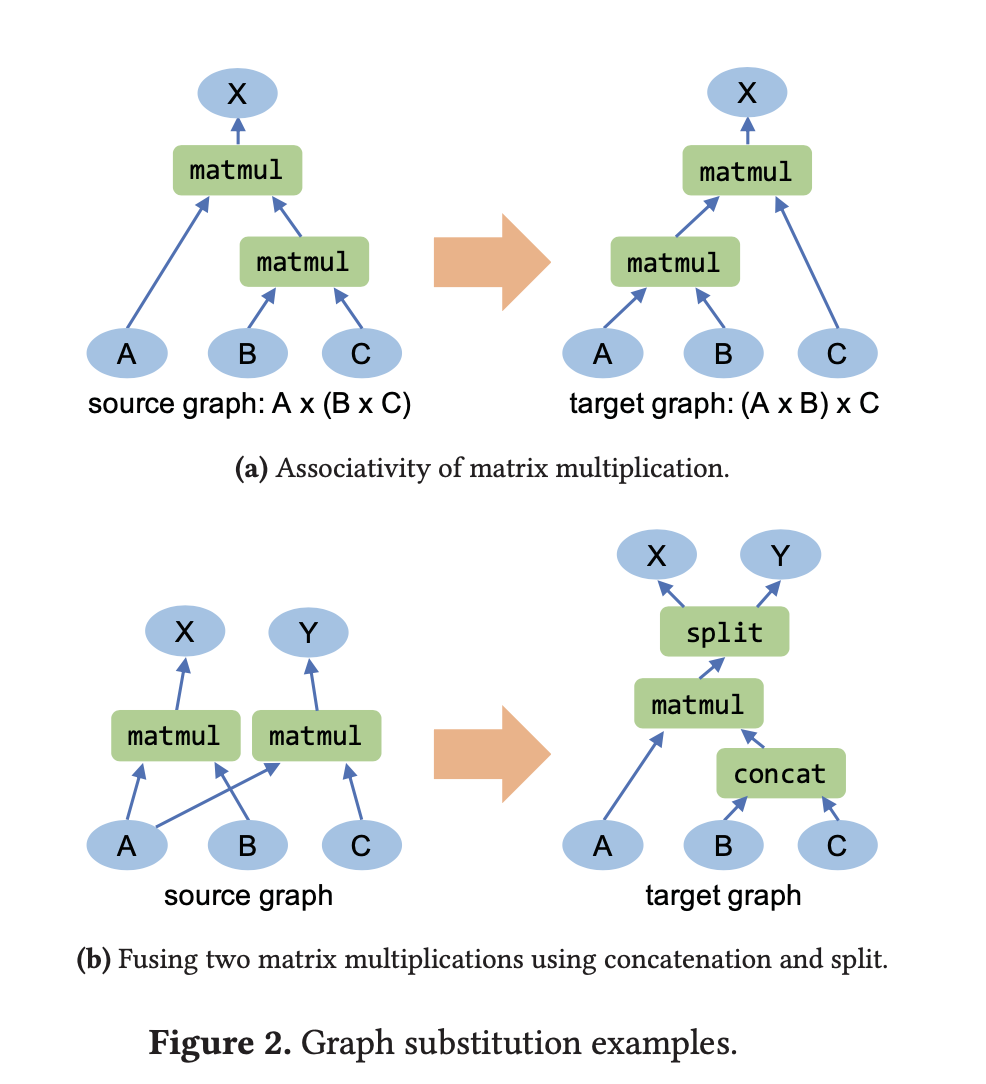
computation graph의 런타임 퍼포먼스를 향상시키기 위해서 할 수 있는 가장 일반적인 방법은 graph substitution이다. graph substitution은 기존 그래프의 일부(subgraph)를 그것과 equivalent 하면서 보다 효율적인 graph로 부분적 치환을 하는 것을 의미한다. Tensorflow, PyTorch와 같은 기존 프레임워크도 이러한 방식을 택하고 있는데 이는 대부분 rule-base의 매뉴얼한 알고리즘을 따르기 때문에 다음과 같은 문제가 있다.
- Maintainability: Hand-written graph substitution은 매우 복잡한 알고리즘을 매뉴얼하게 프로그램 해줘야 하기 때문에 개발, 유지 및 보수에 많은 cost가 발생한다.
- Correctness: 힘들게 만든 graph substitution이더라도 오히려 인간이 만든 것이기에 error가 있을 수밖에 없다. 즉 커버리지 측면에서 문제가 있다.
- Data Layout: 메모리에 저장되는 Tensor data는 실제로 다양한 layout을 가지고 있는데, layout이 어떻게 생겼느냐에 따라서 runtime 성능에 차이가 발생한다. 최적의 layout은 operator와 하드웨어에 달려있는데, 예를 들어 V100 GPU의 경우 conv 연산은 row-major layout이 효율적인 반면, matmul 연산은 column-major layout이 더 효율적이다. 이와 같이 operation & HW dependent한 data layout을 고려한다면, graph substitution 생성에 data transformation을 상황에 따라 다르게 해줘야 하기 때문에 알고리즘이 더욱 복잡해진다.
TASO의 접근 방법
TASO는 위와 같은 문제를 해결하기 위해서 다음과 같은 과정을 거쳐 자동으로(인간의 매뉴얼한 엔지니어링을 거치지 않고) graph substitution들을 생성한다.
1. Generating substitution
TASO의 graph substitution generator는 cuDNN kernel과 같은 DNN operator들에 대해서 모든 가능 조합의 computation graph를 생성한다. 그리고 생성된 여러 개의 computation graph 중 random tensor를 input(operand)으로 주었을 때 동일한 결과값(fingerprint)을 갖는 computation graph들을 모아 candidate으로 설정한다. 이 과정을 효율적으로 수행하기 위하여 TASO는 random input에 대한 output(fingerprint) 값들을 기준으로 hash table을 구성하고, 각각의 entry마다 그에 해당하는 computation graph를 저장한다. Algorithm 1은 duplicate computation(동일한 input tensor에 대해서 동일한 계산을 하는 것)을 포함하지 않는 모든 종류의 acyclic computation graph들을 생성하기 위한 DFS 알고리즘을 보여준다.

각각의 graph에 대해서는 fingerprint(output tensor를 해싱한 것)를 구하는데, 다음과 같이 2개의 해시 함수를 합성하여 사용한다.

동일한 fingerprint를 가진 그래프들에 대해서는 그 다음 단계의 test를 한 번 더 진행한다. 이 때도 앞에서와 마찬가지로 random input tensor에 대해서 두 개의 그래프가 동일한 output를 내는지 테스트를 하는데, 차이점은 앞선 test에선 integer tensor만을 input으로 사용한 반면 여기에선 floating point tensor를 사용한다는 점이다. 두 값의 차이가 특정 threshold(10^{-5}) 보다 작다면 두 값은 같다고 취급한다.
split tree: concat과 split은 동일한 input을 공유하는 operator들을 합치는 데 자주 사용된다. split의 경우 하나의 tensor를 두개의 tensor로 쪼개는 기능을 하는데 이 때 split point를 어디로 잡을지는 input tensor나 parameter만으로는 추정할 수가 없다. 이 문제를 해결하기 위해서 TASO에서는 각 tensor의 각 dimension 마다 split tree를 마치 metadata처럼 넣어주는데, 이를 통해서 과거의 split history를 기억하고 이를 바탕으로 하여 split point를 정할 수 있다. (Figure 3 참고)

2. Formal verification
앞의 두 단계 생성/테스트 과정을 거친 candidate graph substitution들은 verifying step으로 넘어간다. TASO의 graph substitution verifier는 operator property들을 통해서 candidate graph substitution들의 correctness를 확인한다. operator property는 conv 연산의 linearity와 같이 operator의 수학적인 특성을 나타내는데, 이는 유저가 직접 제공을 해야한다. 이 논문에서는 총 43개의 operator property에 대한 예시를 들고 있는데, Table 1은 Tensor operator와 constant tensor의 예시이고, Table 2는 이들에 대한 operator property를 보여준다.


operator property를 유저가 고려해야한다는 점은 다소 복잡하긴 하지만 매뉴얼하게 graph substitution 생성 규칙을 만드는 것과 비교한다면 매우 간단한 편이라 할 수 있다. (각 operator에 대해서 몇 가지의 property만 고려하면 correctness를 보장할 수 있음)
3. Pruning Redundant Substitutions
"만약 어떤 graph substitution과 동일한 더욱 일반적인(general) valid substitution이 존재한다면 그 그래프는 redundant하다"
TASO는 redudant substitution을 제거하고 가장 최적화된 substitution을 뽑아내는 pruning 단계를 거친다. Pruning은 다음 두 개의 단계로 구성되어 있다.
(1) Input Tensor Renaming
Figure 4(a)는 Figure 2(a) 그래프에서 redudant한 부분을 제거한 모습을 보여준다. input tensor C와 A는 이름은 다르지만 같은 값을 지니고 있기 때문에 단순히 input의 이름을 바꿔줌으로써 불필요한 부분을 pruning할 수 있다.

(2) Common Subgraph
그 다음으로 source(변환 전)와 target(변환 후) 그래프가 동일한 subgraph를 갖는 substitution들을 소거한다. 예컨대, Figure 4(b)의 회색 박스 부분을 보면 source 그래프와 target 그래프가 동일한 input에 대해 동일한 operator가 연결된 것을 볼 수 있다. Figure 4(c)는 또 다른 예시를 보여주는데, 회색 칠한 common subgraph는 source 그래프와 target 그래프에서 공통되는 부분이다. 이와 같이 common subgraph를 포함하는 graph substitution들을 모두 후보에서 제거하고 보다 일반적인(general) substitution만 남긴다. 논문에서 제시하길 pruning 이후엔 전과 비교하여 $\times\frac{1}{39}$ 만큼의 substitution만이 남게 된다. (28744개 →743개)
4. Joint optimization
TASO는 graph substitution과 data layout을 하나의 representation으로 통합함으로써 한번에 최적화를 수행한다. 이를 위해서 MetaFlow의 cost-based backtracking search 알고리즘을 다른 data layout에서 기인하는 성능차이까지 cost로 고려하도록 확장한 알고리즘을 활용한다. Figure 5을 보면 source 그래프에 substitution을 적용하여 target graph를 만들 때 data layout을 고려했음을 찾아볼 수 있다. C는 column-major, R은 row-major를 의미한다.

TASO에서는 optimization을 위해서 cost-based backtracking search라는 이름의 알고리즘을 활용하는데 이는 Algorithm 2에서 살펴볼 수 있다. 우선 각 DNN operation의 수행시간을 한 번씩 측정을 하고, 그를 바탕으로 각 그래프의 전체 operator 수행시간이 얼마나 될 지 예측 한다. 이렇게 예측한 수행시간이 해당 그래프의 cost가 된다. (cost가 크다 = 그래프의 수행시간이 길다)
최적의 그래프(G_opt)를 찾기 위한 첫 단계로 모든 후보 그래프들은 우선순위 큐 (priority queue) P에 들어간다. 이 중에서 cost가 큰 것부터 dequeue를 하는데, dequeue된 그래프에 대해서는 substitution을 apply하여 새로운 equivalent graph G'을 만든다. 만약 새롭게 만들어진 G'이 local optimal graph 보다 cost가 작다면 G'을 local optimal graph로 지정한다. 이와 같은 과정을 거쳐서 최종적으로 optimal graph로 남은 그래프가 G_opt가 된다.

이와 같은 과정을 통해 G_opt가 구해지면 G_opt의 cost와 pruning rate를 나타내는 hyperparameter 'alpha'에 따라 나머지 그래프들을 모두 소거(pruning)한다. 즉, 그래프의 cost가 G_opt의 cost보다 alpha배 이상 크다면 그 그래프는 소거된다. 만약 alpha가 1이라면 backtracking을 하지않고 greedy algorithm으로 최적의 그래프를 찾는다. alpha가 커질 수록 search space는 늘어나도 더 많은 candidate를 탐색하게 된다. 연구에서는 실험 결과 alpha=1.05일 때 가장 성능이 좋았다고 한다.
Evaluation

'Research' 카테고리의 다른 글
| PyTorch IR에 관하여 (2) | 2020.03.05 |
|---|---|
| [ASPLOS 2020] SwapAdvisor: Push Deep Learning Beyond the GPU Memory Limit via Smart Swapping (0) | 2020.03.01 |
| [OSDI 2018] TVM: An Automated End-to-End Optimizing Compiler for Deep Learning 논문 정리 (0) | 2020.02.14 |
| 딥러닝에서 메모리를 효율적으로 관리하기 위한 기법들 (2) | 2020.02.13 |
| [Paper Review] Trace-based Just-in-Time Type Specialization for Dynamic Languages (0) | 2020.01.16 |